
8 Pitfalls To Avoid When Interpreting Machine Learning Models
From bad model generalization and correlated features to ignoring uncertainty - many pitfalls can stand between you and a meaningful model interpretation.

Technically, the interpretation of machine learning models is straightforward. Train a model, apply feature importance, Shapley values, partial dependences plot, and other methods.
While technically easy, it’s also easy to make mistakes, that range from using unsuitable ML models in the first place, inherent limitations of interpretation methods, or plain wrong application of a method.
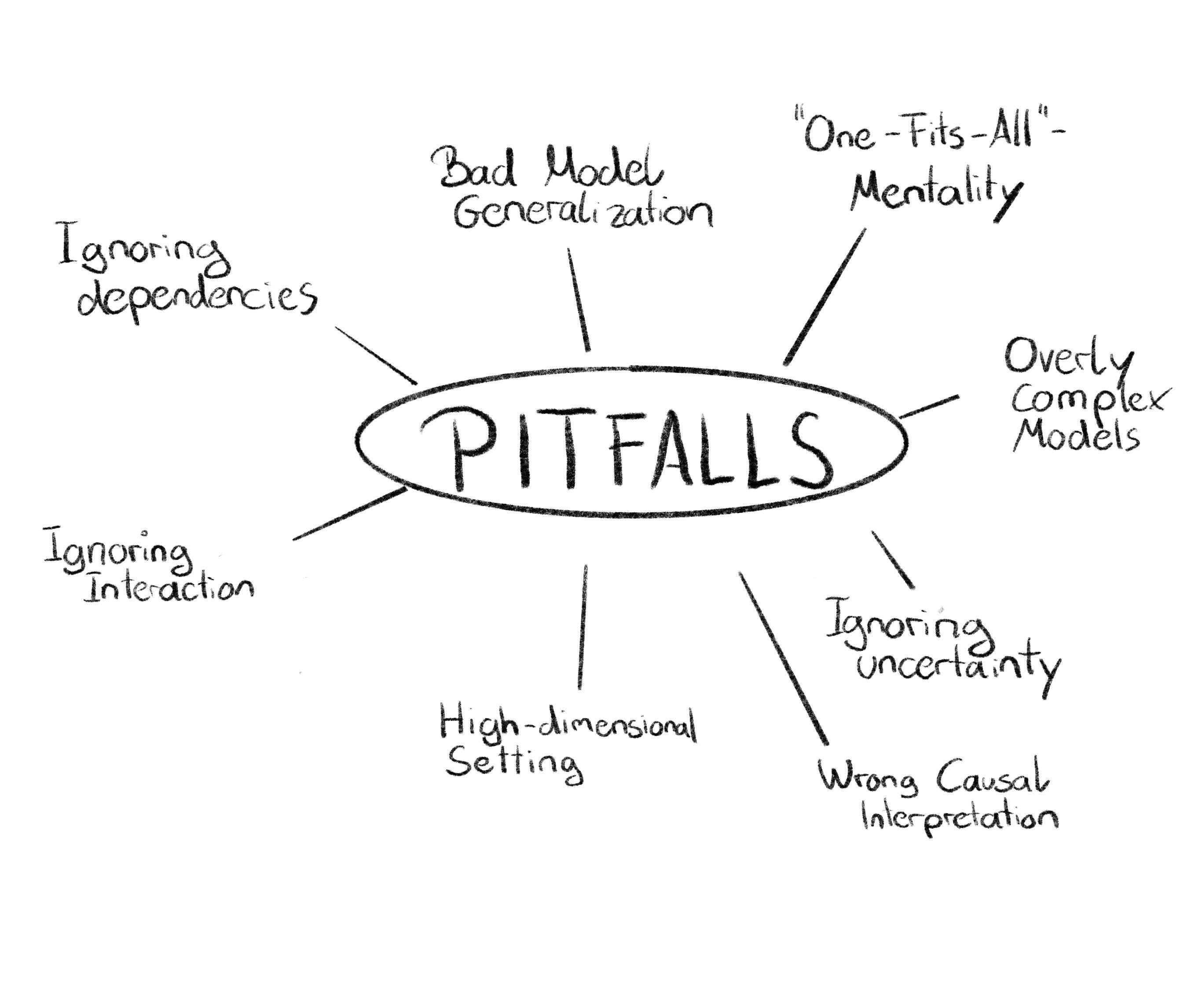
Here are 8 pitfalls that apply to most (model-agnostic) interpretation methods such as LIME, SHAP, PDP, permutation feature importance, …
Let’s dive in.
Pitfall #1: Assuming that 1 method is the best for all interpretation contexts.
I’m looking at you, SHAP user 😉.
Interpretation methods target different notions of interpretability. My favorite example is the difference between permutation feature importance (PFI) and SHAP importance. Both have importance in their names which describes some idea of ranking features by how relevant they were. But they rank features differently: PFI is loss-based, and SHAP importance expresses more how the output varies. If a model overfits on a noise-features, PFI should be zero, while Shapley importance should say the feature was important (and that’s fine). Both importance rankings have different goals.
Solution: Define the goal of the interpretation and choose the right interpretation method. Not the other way around.
Pitfall #2: Interpreting a model that doesn’t generalize.
This pitfall applies if you interpret the model to learn something about the data. However, if the target of interpretation is a specific model, like for model auditing or debugging, this pitfall doesn’t apply.
If a model under- or overfits the data, any interpretation applied to that model will be affected by this lack of generalization. SHAP values may show effects that aren’t in the data but the model used the feature nonetheless (overfitting). Permutation feature importance underestimates the most important feature because your model didn’t capture interactions (underfitting).
Solution: Use proper out-of-sample evaluation like cross-validation. Don’t implement resampling yourself, but use software packages (less room for errors).
Pitfall #3: Using an overly complex model when a simple model would have been sufficient.
New and fancy machine learning models have a high level of attractiveness for data scientists. At least that’s true for me. But if a simpler model is sufficient, it’s preferable for, among many other reasons, better interpretability — even if you use model-agnostic interpretation methods. For example, a partial dependence plot is easier to interpret if the feature doesn’t interact with other features (see pitfall #5).
Solution: Always try out simpler baseline models. Only use a more complex model if the trade-off between loss in interpretability and gain in predictive performance is justified.
Pitfall #4: Ignoring feature dependence.
Many interpretation methods fall into the extrapolation trap: model-agnostic methods such as PDP or Shapley values manipulate data, and if the features are correlated the methods can produce unreasonable data points. This can be fine if the goal is model audit, but if the goal is to understand relations in the data, these unlikely data points shouldn’t be part of the interpretation.
Some interpretation methods are adapted for the correlated case. However, this changes the interpretation. For example, permutation feature importance has a different interpretation from conditional importance. I dedicated an entire issue to how correlation can ruin interpretability since it’s such a widespread interpretation problem.
Solution: Analyze dependencies in the data, use interpretation methods that can deal with correlated features, and interpret them correctly.
Pitfall #5: Misinterpretation due to interactions.
Many interpretation methods just average over interactions or ignore them. For example, 1D partial dependence plots don’t show interactions, and a feature might have a “flat” effect curve. It would be wrong to assume that no matter how you change the feature it doesn’t affect the prediction. Because it might have a strong interaction with another feature, so changes to the feature can change the output.
Solution: Learn how interpretation methods deal with or hide interactions. Use interpretation methods to specifically study interactions.
Pitfall #6: Ignoring the uncertainties of the interpretation method and model training.
Interpretation methods are estimated from data and therefore have variance. Also, the model is subject to uncertainty, since it’s trained on a random sample. Also for this pitfall, we have to distinguish between model auditing and interpreting the model to learn about the data or the world. In the latter case, we have to take into account that the model has uncertainty and would look different if retrained with a different sample from the same distribution. For both cases, the estimation variance of the interpretation methods should be taken into account.
Solution: Report uncertainty due to interpretation estimation and (if applicable) the uncertainty due to model training.
Pitfall #7: Failing to scale interpretation to high-dimensional data.
Interpretation methods often work fine if you have only a few columns, but if you have more, then things become tricky. It’s impractical to look at thousands of partial dependence plots and computationally expensive to compute Shapley values in such high-dimensional settings. Further, similar problems as in multiple testing occur: the more results and interpretations there are, the more likely there are false positive findings.
Solution: Use dimensionality reduction, group features, and correct for multiple testing.
Pitfall #8: Interpreting a non-causal model.
Interpretation techniques can make it more tempting to interpret features as causal. But the same as with statistical models such an interpretation is only permitted if the machine learning model is a result of a casual model and has undergone causal identification, such as making sure that all confounders are included.

Solution: Assess whether causal assumptions about data and model hold, and also whether the interpretation method is suitable for a causal interpretation.
That’s a wrap.
If you want to dive deeper into each pitfall, read our paper General Pitfalls of Model-Agnostic Interpretation Methods for Machine Learning Models.
If you care to learn more about interpretation methods in general, you could get my book Interpretable Machine Learning from Amazon.