
Audit Or Insight? Know Your Interpretation Goal
Interpretation can be true to the model or true to the data. Which interpretation you need depends on whether you want to audit your model or gain insights.

Model interpretation is done for various reasons. Two big categories are:
Auditing a model
Gaining insights through a model
Interpretation methods such as SHAP, permutation feature importance, and partial dependence plots can be used in both scenarios.
Audit versus insights has an implication on how to deal with correlated features, a topic in interpretable machine learning that has followed me throughout my Ph.D.
In this post, you will learn:
The difference between audit and insight.
What the choice has to do with correlation.
Let’s dive in.
Auditing A Model
For this post, I refer to auditing in a broad sense including any type of probing of the model, seeing how it “behaves” when the input features change. Some examples:
A bank implemented a logistic regression model for credit scoring and needs to report important features and feature effects.
A data scientist studies the permutation feature importance of a model to “debug” the model and get some ideas for feature engineering.
An engineer suspects that a classification model in production might be misused and tries to find some adversarial examples.
In these cases, the model itself is the target of interpretation. It’s important that the interpretation is based on the model used in production.
If you’ve read my post about how interpretation can ruin interpretability, you know that many interpretation methods create new data points. If features are correlated, methods like SHAP or partial dependence plots create unrealistic data points, because features are changed while ignoring dependence structures.
But for the model audit, the interpretation needs to be true to the model.
For example, if a feature isn’t used by the model, its estimated effect and importance should be zero. For a linear regression model, a feature effect plot that is true to the model should show a linear function with a slope according to the model coefficient.
Let’s have a look at a partial dependence plot
The model is f(x) = x1 - 0.1 x2 + x3. Features x1 and x2 are highly correlated.
The partial dependence plot (PDP) is a feature effect method that is true to the model. At each value of x2, the PDP shows the average prediction if every data point had this particular value for x2. In the plot, the PDP (bright dashed line) shows a line with a -0.1 slope, which is true to the linear regression model. But the PDP also includes unrealistic data. For example, for x2=2 data points were created where x1=-2, which is unrealistic because x1 and x2 are highly correlated.
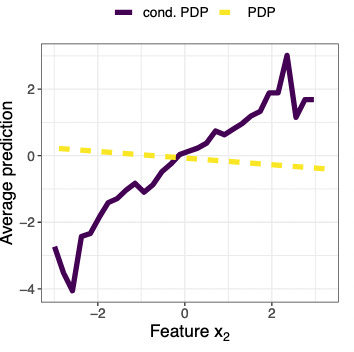
The purple line shows the conditional PDP or M-Plot. Instead of ignoring dependence, the cond. PDP works by only averaging over realistic combinations of x1 and x2. It’s not true to the model: it shows an increasing slope, which is not true to the model at all.
Which of the two curves is more “truthful” when it comes to gaining insights about the data? Since x1 and x2 are highly correlated, they are more or less inseparable for interpretation. The cond. PDP reflects this mixed effect of x1 and x2 and combined with the knowledge about correlation, it’s more insightful about the data.
Gaining Insights
When the focus is on generating insights, the machine learning model is just a means to an end. Some examples:
A scientist uses a prediction model to find out which genes are associated with disease occurrence.
A data scientist forecasts sales of Kimchi and wants to leverage the model to sell more.
An ecologist models the occurrence of oak trees in Germany and wants to understand climate factors that influence the occurrence.
All examples use machine learning, but the modelers also want to answer questions.
Insights require an interpretation that is true to the data because an interpretation using unrealistic data should — almost by definition — not be used for making claims about reality.
Many interpretation methods are true to the data:
Conditional feature importance
TreeSHAP with feature_perturbation=”tree_path_dependent”
M-Plot / conditional PDP
Leave-one-covariate-out (LOCO)
…
However, being true to the data also means that the interpretation of a feature is entangled with all features that it is correlated with. This entanglement is undesirable in science and elsewhere: It’s easier to understand features in isolation. But the world is entangled, and we have to deal with it.
Independent Features and Other Solutions
If features are independent, true-to-model and true-to-data are one and the same, which is damn convenient. Because we get both an “isolated” interpretation and only use realistic data points for interpretation.
Many attempts to “fix” correlated features work towards uniting true-to-model and true-to-data:
removing correlated features
grouping correlated features for interpretation
using specialized approaches such as PDP/PFI in subgroups
…
Getting an interpretation that is true to the model and data is, of course, the ideal case. In practice, however, it’s not always possible to bring these two together. Instead, you will have to decide whether it’s the audit or insights aspect that is more important to you.
To dive deeper into the debate about true-to-data versus true-to-model, I recommend this paper, which coined the terms (I believe), with a focus on Shapley values.
Before you go
My new book Modeling Mindsets will come out soon. Just today it came back from proofreading, so it’s almost done. If you want to get notified when the book is available, you can sign up here: