
Fixing Bias: How Error Analysis Improved My Water Forecasting Model

The western United States has a huge water problem. That’s why much effort goes into managing the water properly, including forecasting a season’s water supply. The Bureau of Reclamation, which manages water and power in the West, sponsored a machine learning competition on DrivenData to improve the forecasts. I thought it would be fun and participated. Turned out to be a lot of work and super stressful, and I probably won’t win a single cent, but that’s a story for another day. 😅
Months into the challenge my models’ performance looked good. But then I did a deeper analysis of the model errors and found that the models had some strange error patterns.
To understand this error pattern, I must first explain the forecasting task. The task was to predict the water supply for 26 sites in the western United States (such as Libby Dam), measured as the total amount of water flowing between April and July.
An interesting aspect of water forecasting is that forecasts are issued weekly from January 1st to the end of July, but the target remains the same: the total flow at each site between April and July. This gives the forecasting task a temporal structure without being a classic time series task.
The closer the issue dates are to the end of the season (end of July), the more information there is about snow status and previous water flow. I trained an xgboost model for all sites and issue dates together. Well, 3 models actually since we needed to predict 10%, 50%, and 90% quantiles.
I analyzed performance by site and issue date and found a strange bias. But see for yourself:
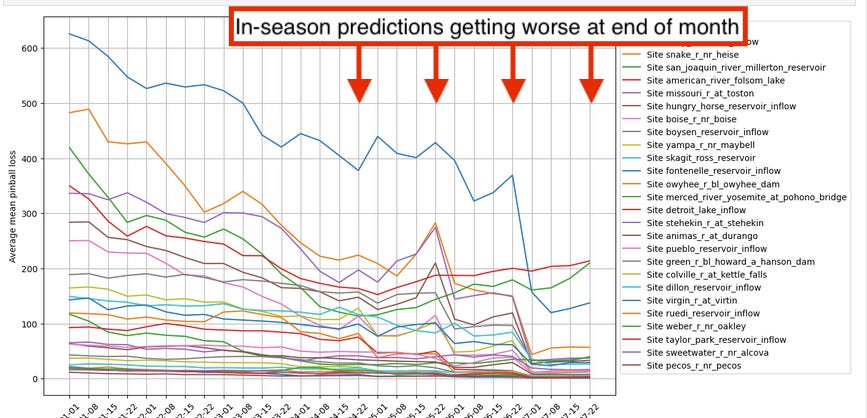
The graph shows the issue dates on the x-axis and the model loss (average pinball loss) on the y-axis. Each line represents the errors for one site (averaged across multiple years).
What I expected: The error should decrease as the issue dates get closer to the end of the season. There should be a sudden improvement when going from April to May, May to June, and from June to July since then the flow of the previous month is known and can be incorporated into the prediction.
What actually happened: There are some periods where the loss goes up over time and even spikes quite sharply. For the in-season months of April, May (the worst!), June, and July, the error goes up within the months. This shouldn’t happen.
It took me a while to figure this one out, but it was basically a feature engineering problem with the snow features. The most important feature is the snowpack estimate: How much snow mass is currently available in the mountain ranges that feed the various rivers and dams?
Let’s compare two issue dates: May 1 and May 22.
Let’s say there is lots of snow in the mountains around May 1st. The snow feature correctly reflects that there is a lot of snow, so a large water flow is forecast.
By May 22, much of this snow will have melted. The snow feature now says: not much snow available. Compared to May 1, the target hasn’t changed, it’s still to predict flow from May through July. However, the model has no information that there was a lot of snow at the beginning of May and can’t account for it.
I fixed this end-of-month melt bias with better feature engineering of the snow features and then the errors looked like this:

Much better! Still not a money-making model performance, but at least I got rid of that bias.
Lessons learned:
Always perform error analysis → I wouldn’t have found the end-of-month bias without it. Error analysis is something many modelers do naturally, but I feel like this topic is underexplored. Might do another post on this topic if you are interested.
Try to name biases and errors → Naming makes it easier to communicate. We had to write a report for this competition and I mentioned the end-of-month melt bias there. I believe it might also affect some of the models that are currently used, so I thought it worth naming and communicating this bias to the hydrologists.
Be mindful when feature engineering → In hindsight, I might have caught this error if I had thought more deeply about the features. But maybe I’m being too hard on myself here 😂
Timo and I covered many topics relevant to this competition, such as uncertainty, interpretability, and domain knowledge in our upcoming book Supervised Machine Learning for Science. One good thing that came out of this competition was that it gave me confidence that our new book will cover topics that are relevant not only to scientists but to anyone who needs more than just model performance. We will publish it this fall and it will be available as a paperback and an e-book.
This is good!
One reason I think people don’t do error analysis is there’s no recipe for it. You just have to be smart and resourceful and understand the domain. In contrast for all the previous steps of the ML pipeline there are standard recipes and many steps are even automatable.