
How to deal with non-i.i.d data in machine learning
Ignoring this common problem can lead to data leakage, overfitting, and overly optimistic evaluation.

If you want a convenient life as a machine learner, I recommend exclusively working with independent and identically distributed data (i.i.d.).
Well, usually you don’t have a choice. More often than not the data looks like one of these examples:
You have survey data from students. Some students are in the same class and therefore correlated.
You forecast monthly sales and the dataset includes multiple sales data points per store.
You are working with image data and the objects are photographed from different angles.
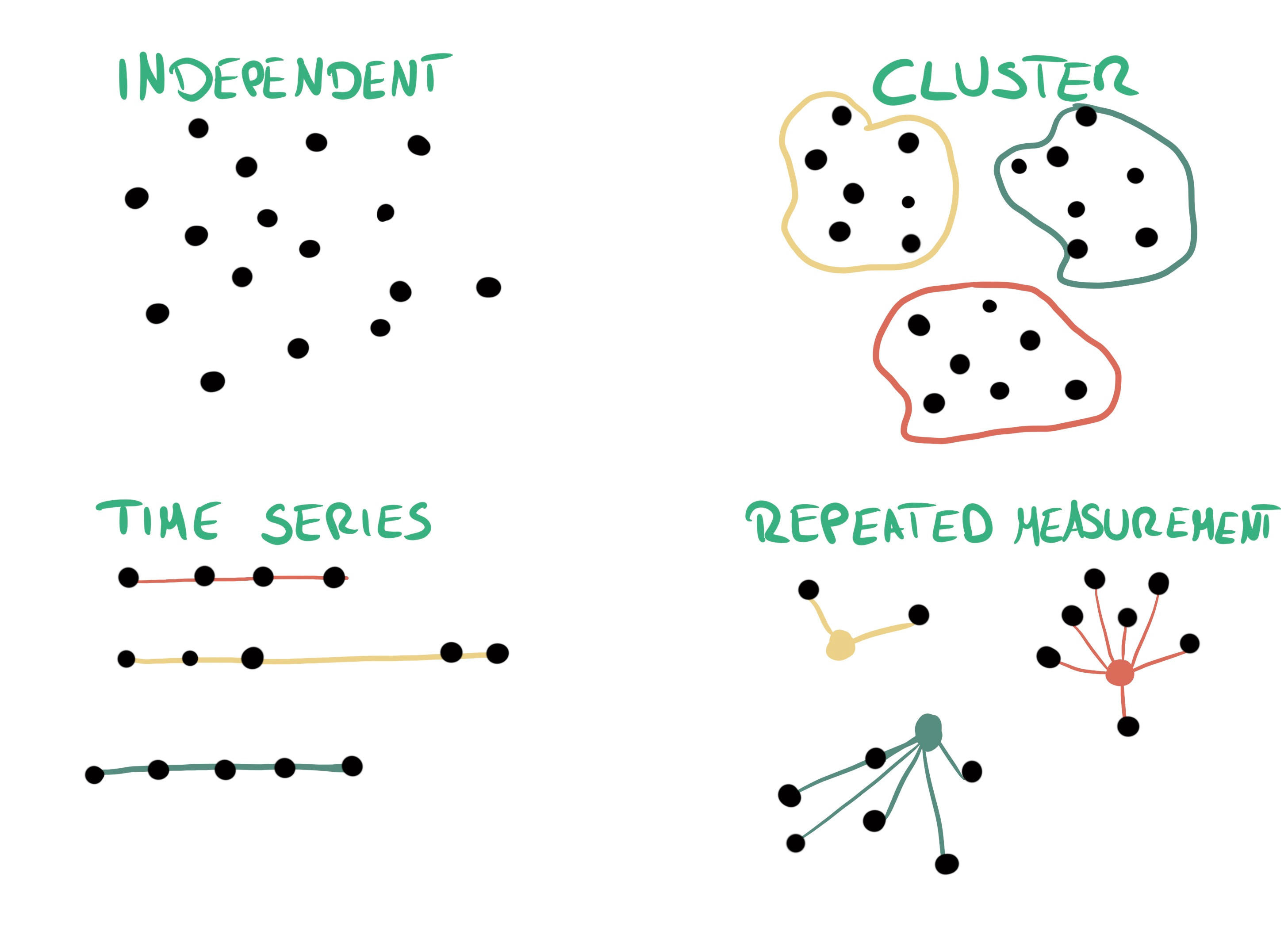
In these examples, the data points are in discrete groups: There may be a hierarchical structure that clusters the data points (e.g. schools → students), objects/subjects may be measured repeatedly (objects photographed multiple times), or multiple rows may belong to the same entity tracked over time (e.g. monthly sales per store).
How do you model data with such dependencies?
If you opt for classical statistical modeling, you have a go-to approach: Mixed effect models. Also known as hierarchical models, multi-level models, random coefficients, nested models, and panel data models. Mixed effect models account for the dependence structure in the data to correctly estimate coefficients.
But what if your model is a gradient-boosted tree ensemble spit out by xgboost, or a trained transformer model, where we don’t care about coefficients?
Can we ignore dependencies for prediction?
Well, you can. But if you ignore dependence structures, your training process might suffer from row-wise leakage. This leakage may lead to overfitting and over-optimistic performance evaluation.
Whether row-wise leakage is a problem depends on how the model will be applied in the future and how data splitting (e.g. cross-validation) for tuning and evaluation is performed.
If you predict students’ grades and there is a strong “classroom effect” (bc. some teachers generally give higher grades), then the ML algo will try to learn to identify the classroom, even if you don’t have the class id as a feature. However, depending on the model use case, learning the classroom effect may be desired or not.
Suppose the model is used to predict grades for students from unseen classrooms. In that case, you have a group leakage problem: If you ignore the classroom structure when splitting into training and test, students from the same classroom end up in both training and test. The consequence: the test performance will be over-optimistic and you will select models that are good in identifying the class a student is in. The solution: the splitting should happen by group (here: student class) so that one group is either in training or testing. In terms of code, you might use something like GroupKFold from sklearn.
However, if the future model application will be on students from the same classes as in the training data, having students from the same class in both training and testing may be fine.
The bottom line: Your data splitting setup must match the real-world use case of your model.
The same goes for time series: If your goal is to forecast the time series only for entities in your training data, then you want to have the same entity in both training and testing. Carefully sliced so that training data contains earlier time points than testing data (e.g. sklearn.model_selection.TimeSeriesSplit).
But if your goal is to apply your model to new entities (e.g. stores), then you want to make sure that an entity’s time data is either in training OR testing, but not both.
I’m just beginning to explore the non-i.i.d case for machine learning. When it comes to non-i.i.d data, a suitable design for data splitting and evaluation is important, but there are a lot more questions, especially when it comes to interpreting models:
Can we use interpretation tools like SHAP or PFI in the same way as for i.i.d. data? Or do we have to adapt them?
Do we have to interpret features that describe a row differently from features that describe the group? For example, you might have feature importance for the feature “time spent reading by student” (describes row) and “years of experience of the teacher” (describes group).
Are there biases when interpreting e.g. feature importance in non-i.i.d. data?
I’m looking forward to exploring these questions and I’ll share any insights with you.
Have you worked with non-i.i.d. data before? Do you have any tips or stories you can share on how you dealt with the dependence?
Hey Christoph, great post.
One of the most common mistakes I see people make with respect to non-i.i.d. data is with data augmentation. As you explain in the post, the details of the data splitting are crucial. In NLP projects I have often seen people augmenting their data and then cross validating on that augmented set. However, this order of execution leads to examples that are small variations of the training data to leak into the test set. This way, augmentation always seems to improve the system 😏. To assess the effect of augmentation on test performance correctly, however, you have to first split the data and then only augment your training data.
In economics, group dependencies like classroom effect that you've mentioned are taken into consideration. When they do modelling they usually go for wild cluster bootstrap.
There is a R package called fwildclusterboot made by Alexander Fischer and David Roodman. Their package is based on https://econpapers.repec.org/paper/qedwpaper/1406.htm ( Roodman et al (2019)) and https://www.econ.queensu.ca/sites/econ.queensu.ca/files/wpaper/qed_wp_1485.pdf (MacKinnon, Nielsen & Webb (2022))