
Should we stop interpreting ML models because XAI methods are imperfect?
The Case for Imperfect Interpretability

Every once in a while I come across “explainability perfectionism”. In its extreme form explainability perfectionism says we shouldn’t rely on explainability methods for machine learning, because we haven’t perfectly defined what they do or target.
Examples of explainability perfectionism:
Permutation feature importance: We haven’t even defined “ feature importance” yet!
SHAP: We don’t know what a perfect attribution method looks like.
Partial dependence plot: When features are correlated the PDP might be misleading.
I agree with these criticisms, but mostly as guidance for future research, or as a critique of some current research.
But when it comes to applying these methods, explainability perfectionism is a sure way to never get anything done.
I once worked together with a “perfectionist statistician”. We consulted clients on which statistical analysis to use. He would start proposing statistical models, adding requirements (e.g. “We need mixed effects because we have repeated observations”), but at some point, he would just list (unsolvable) limitations with the proposed approach. Stating limitations is good, in general, but at some point, you have to be pragmatic and make a decision, which was sometimes difficult with him.
When it comes to modeling practice, you have to become a pragmatist. Because if you work on machine learning in practice, it’s typical to come across the need for interpretability.

Execpt for one possibility that we have to check first: If we do more harm than good when interpreting a model, then the pragmatist would agree not to use the method.
Is an imperfect model interpretation better than no interpretation at all?
You will find plenty of papers showing that XAI methods can be misleading in certain scenarios. Is that enough to discourage the use of those methods?
In a moment of grand youthful stupidity, I once touched the toaster heating element with a spoon. Not by accident, but on purpose. Not because I planned to harm myself, but because I was waiting for my toast and my curiosity told me to let water drop on the heating elements to see them cool down for a second. 0 out of 5 stars, can’t recommend getting shocked by your toaster. Fortunately, the fuse had blown out and stopped the flow of electricity. I emerged unharmed from this mistake.

Even with this bad experience, I still think toasters have a net benefit.
Clearly, just because you can show a specific scenario in which an interpretable ML method or toaster can be harmful, it doesn’t mean that the method or toaster should not be used at all.
Whether explainability methods are net negative or positive is quite unfeasible to show, because for this we would need a representative sample from all actual applications of those methods and come up with a way to measure success.
Thinking to much about explainability perfectionism may even lead to “explainability nihilism”: the idea that all XAI methods are doing something arbitrary and crumble if you look at them for too long.
But this runs counter my experience:
The PDP, for example, has, in theory, trouble when features are strongly correlated. ALE is an alternative to visualize feature effects when features are correlated. But my experience so far is that even for correlated features both effect curves didn’t look that different in most cases.
If you use different interpretation methods, say permutation feature importance to rank the features, partial dependence plots to visualize feature effects, and SHAP for explaining predictions, they usually showed a quite coherent picture of the model mechanism.
These examples are anecdotal, so let’s look at one example from a more theoretical stand point: SHAP is a method to explain individual predictions and SHAP values can be combined to produce effect plots that show how a feature affects the predictions on average.
The perfectionist’s critique would be: We don’t know what SHAP expresses! We don’t know whether people understand it. Don’t use it.
But are SHAP values really such unknowable, mythical things?
Say, we have a linear regression model. What do the SHAP values look like for this linear model?
Well, they are simply the coefficient multiplied by the value of the feature, minus the average effect for that feature
And if you plot the SHAP values of your data against the the feature values, they just replicate the slope of the coefficient:

The same goes for additive models, like generalized additive models (GAMs). Here the SHAP values (blue dots) match the spline curve (red curve):
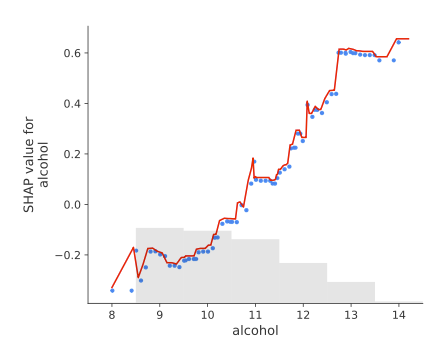
These examples are from my book Interpreting Machine Learning Models with SHAP, and they show that for these simple models, SHAP values match quite well with what we would expect. When the model covers interactions between the features, the interpretation becomes a bit tricky as I explain in the book, but the overall story is that SHAP is well connected with what the model actually does.
While we should strive for more rigor in XAI research, in practice we should use the imperfect methods as long as they provide a net benefit.