
TabArena explained
What chess ratings tell us about ML models

Machine learning progresses through benchmarks. While I’ve been critical before of ML’s benchmark obsession and danger of getting stuck on benchmarks, benchmarks are essential to guide researchers and practitioners in the right direction. ImageNet, under the leadership of Fei-Fei Li, for example, ushered in the deep learning era. Also today, LLMs are largely driven by benchmarks, like Humanity’s Last Exam or LiveCodeBench (coding).
With the rise of tabular foundation models, a benchmark that often comes up is TabArena. Tabular, of course, is already way more mature than deep learning was in 2012. However, TabArena still introduces a new dynamic and is a change from other tabular benchmarks. For example, two days ago, Prior Labs announced TabPFN v2.6. A huge part of that announcement was the TabArena placement of the new model (first spot). TabArena has become a central element in the paradigm shift to tabular foundation models.
So what is TabArena? Let’s find out.
TabArena “lives” on HuggingFace
TabArena is a “living” benchmark, and you can find it in its natural habitat on HuggingFace. It’s by far not the only tabular benchmark; there have been many before it, like OpenML-CC18 or Tabzilla.
These benchmarks have been crucial in advancing machine learning. Tabular benchmarks, at their minimum, define a collection of ML tasks connected to datasets. What sets them apart from a pure dataset repository, like UCI, is stronger curation of datasets, and sometimes a benchmarking protocol, e.g., for how to evaluate models.
TabArena is probably the benchmark with the strictest protocol and thoroughness:
TabArena standardized the pre-processing and evaluation procedures.
It also includes ensembles for each model (except TabICL and TabDPT).
Has the highest limit for tuning and training the model, meaning more confidence that the search is maxed out.
Not only metric results, but also predictions are available.
What makes it “live” is that it’s an actively maintained benchmark. Not just a static table in a paper, but a space on HuggingFace that the TabArena maintainers update with new ML algorithms and tabular foundation models. TabArena was created by researchers from Amazon Web Services, the University of Freiburg, the University of Mannheim, INRIA Paris, Ecole Normale Supérieure, the ELLIS Institute Tübingen, and Prior Labs. The core maintainers are Nick Erickson, Lennart Purucker, Andrej Tschalzev, and David Holzmüller.
TabArena pits ML algorithms against each other
TabArena rates ML algorithms and foundation models using an Elo rating system, which you might know from chess or other competitive games. Elo is for pairwise comparisons, and the rating of an ML algorithm / TFM can be interpreted as the expected win probability for a task. Winning, as in producing a better model than another algorithm on a given task. The following figure shows the data going into the Elo ranking. For example, TabICLv2 was beating CatBoost in 76% of tasks, or, inversely, CatBoost was beating TabICLv2 in 24% of the TabArena tasks.
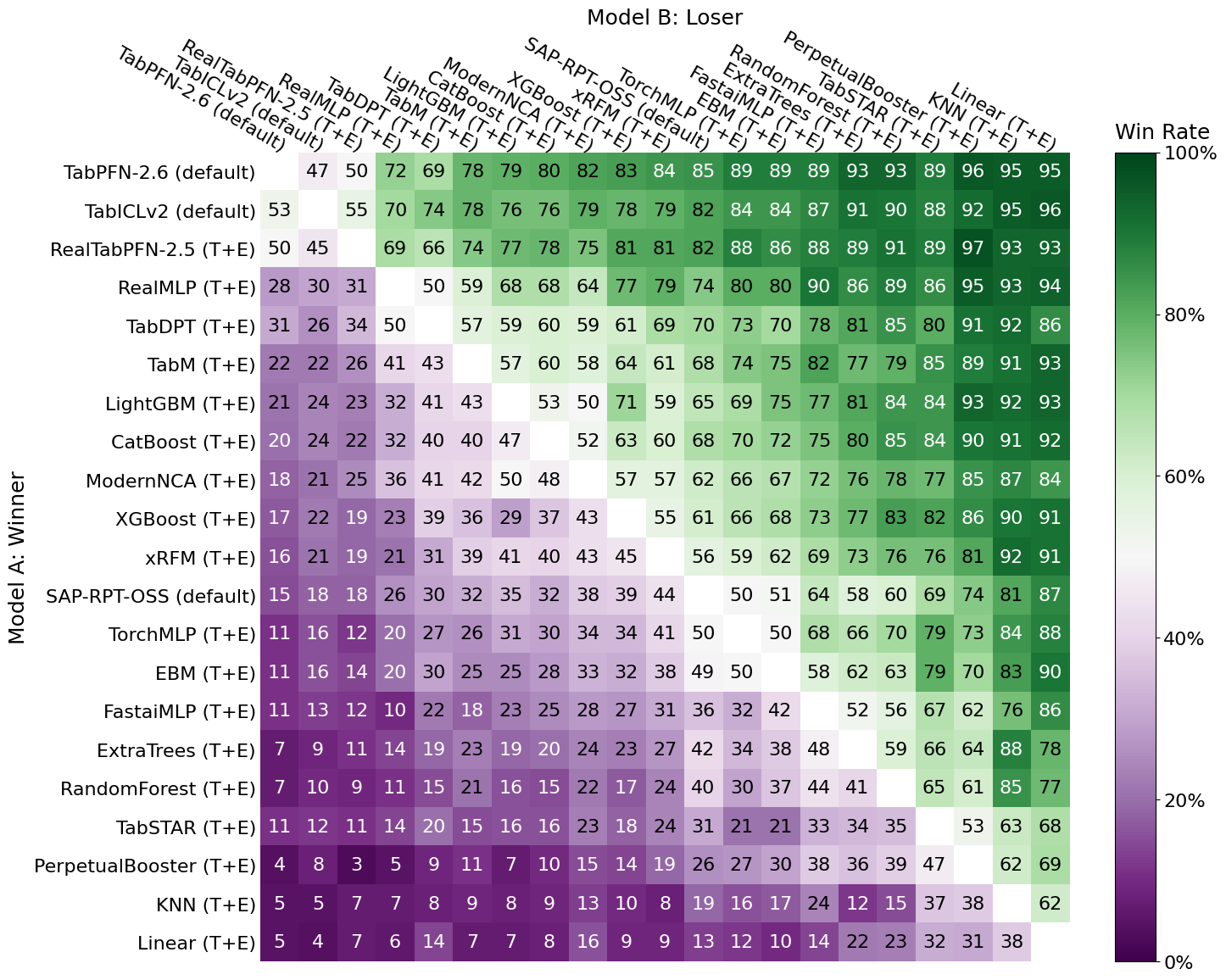
Elo reflects well how we select models in practice. When we compare models for a project, we want one that beats the others in terms of performance. There may be other constraints, such as interpretability and computational performance, but predictive performance ranks high. Elo only counts wins versus losses (or ties), but not by which margin. If two algorithms have the same win rate, their Elo will be the same, even when one algorithm fails catastrophically on the losses, and the other always comes in second by a small margin. This, however, is covered by other metrics on TabArena, such as improvability.
TabArena contains 51 tasks
TabArena benchmarks ML approaches based on 13 regression and 38 classification datasets.
Sounds small.
Especially small, given the amount of tabular data flying all around. To be fair, most of them are locked up in companies. You won’t find Aldi sales data, OpenAI churn tables, or spring coil test datasets flying around the internet with an open license. But still, OpenML hosts over 6k datasets! The only problem is: once you start being just a little selective, the number drops fast.
The TabArena team started with 1053 datasets and sequentially filtered them down:
They removed 491 duplicate datasets.
135 datasets were tabular only in disguise: they were actually derived from other data modalities like images.
The team removed another 123 for lack of a real predictive task (e.g., deterministic outcomes).
Tiny data, quality issues, incompatible license … meant another 181 were excluded.
Of the remaining data, they reduced 70 non-IID datasets.
Leaving only 51 datasets after this manual process, see also the TabArena paper.
TabArena snapshot
Let’s finally have a look at the current leaderboard of the overall benchmark:
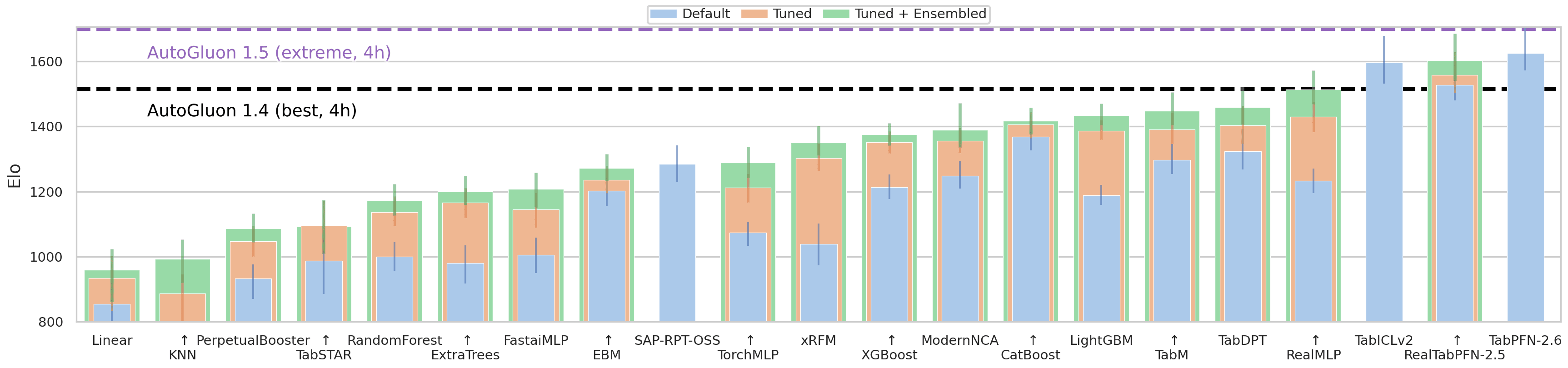
Current ceiling: AutoGluon 4h extreme. AutoGluon is an open-source AutoML framework by AWS, and “4h extreme” is a preset that allows up to 4 hours of training time with the most intensive ensemble and hyperparameter search settings for maximum predictive performance. The top 3 positions are all tabular foundation models: TabPFN 2.6, RealTabPFN-2.5, and TabICLv2. All the way down at position 7 appears the first boosted tree algorithm with LightGBM. Reminder: Elo rankings don’t tell us about the absolute differences in performance. Also, the number of datasets is a caveat, and keep in mind that TabArena represents small to mid-sized IID data. Nonetheless, still impressive how far tabular foundation models have come.
If you want to dive deeper, there is a TabArena presentation on YouTube.
Any specific advantage of using elo like benchmarking instead of general benchmarking like how we do with LLMs?
Thanks for this article presenting TabArena, very instructive !
Looking at its recent use for modern AutoML and TFMs models, I have some questions about TabArena:
- How diverse and representative are these final 51 datasets regarding real use case scenarii ?
- How can we ensure that one (or several) of these validation datasets is not highly similar to one of the synthetic datasets the TFMs were pre-trained on (which could lead to data leakage and over-optimistic performances assessment) ?
- As Cassie Kozyrkov explains in one of her ML lectures, "repeatedly validating model after model pollutes your validation data and erodes your protection against overfitting". In this case, is it planned to add or change datasets in TabArena to ensure newer models may not overfit on the validation sets ?
Curious about your thoughts on these questions :)