
The Statistician Who Loved Machine Learning
A Different Interpretation of a Classic by Leo Breiman

The best argument for machine learning was made by the statistician Leo Breiman. But there’s another story underneath that’s often overlooked.
Let’s revisit his classic Statistical Modeling: The Two Cultures.
The Two Cultures
Leo Breimann was trained as a classic statistician but then left academia for industry. There he fell in love with machine learning. Inspired, he returned to academia to invent CART and Random Forests among other great things. He is also known for his paper Statistical Modeling: The Two Cultures.
The paper starts with the following problem statement: We have input variables X and response variables Y. “Nature” maps from one to the other:

The goal: Find a function f() that can predict Y from X but also get an understanding of the mechanism.
Leo Breimann names two “cultures” of statistical modeling to approach this goal.
The Data Modeling Culture: The modeler assumes a stochastic model for the data. For example that Y given X follows a Normal distribution. The modeler tries to find out the mechanism of nature and fills in the statistical model. The statistical model is then interpreted in place of nature.

The Algorithmic Modeling Culture: The modeler assumes “Nature” to be potentially complex and unknowable. Instead of assuming a functional form, an algorithm f(x) is searched to approximate the behavior.

Leo Breiman argued that statisticians focus a lot on the data modeling culture, but should focus more on the algorithmic modeling culture. His thinking was shaped by industry projects, which he also talks about in the paper.
He gave many reasons why statisticians should focus more on the algorithmic modeling culture:
Goodness-of-fit tests and residual analysis used in the data modeling culture don’t reliably catch problematic assumptions.
Often multiple models fit the data equally well, posing a challenge to the “let’s figure out the data-generating process” mindset.
The algorithmic modeling culture requires fewer assumptions about the data distribution.
Model selection and validation prevent overfitting and give a realistic picture of a model’s predictive performance.
The algorithmic modeling culture is close to what I would call machine learning, and the data modeling culture is akin to classic statistical inference.
The paper is often interpreted as an “advertisement” for machine learning (aka algorithmic modeling culture). At least that was my interpretation for a long time. But deeper down, there’s another, more powerful message about being pragmatic when it comes to modeling.
Machine learning is not the ultimate mindset
Leo Breiman advertised the algorithmic modeling mindset to a crowd that was mostly sold on “classic statistics” like frequentist or Bayesian inference. So Leo Breimann, in my opinion, doubled down on the algorithmic modeling mindset to counterweight the dominant data modeling culture.
But he wasn’t saying that one should only use algorithmic modeling. He wrote:
“I am not against data models per se. In some situations they are the most appropriate way to solve the problem. But the emphasis needs to be on the problem and on the data.” — Leo Breiman
So he advocated for being problem-focused instead of solution-focused. No culture or mindset is the best for all occasions. Rather the modeler should pick the appropriate mindset to get the job done. Pragmatic. I think that’s the ideal description of a data scientist: someone who knows when to pick which modeling approach.
So while Breimans paper was a big advertisement for machine learning aka algorithmic modeling, I also see his landmark paper as something else: A call for pragmatism and being open to many modeling mindsets (or at least the two he mentioned).
Be a pragmatic modeler
But the big problem is that it takes a long time to understand the different mindsets. And it’s not just statistical inference versus machine learning. Statistical inference has different flavors: Bayesian, frequentist, and likelihoodist. Machine learning also has many flavors, like supervised, unsupervised, and reinforcement learning. While these “flavors” have a lot in common, they differ quite a lot in how they make you think about the world, which problems they can solve, and which limitations they have.
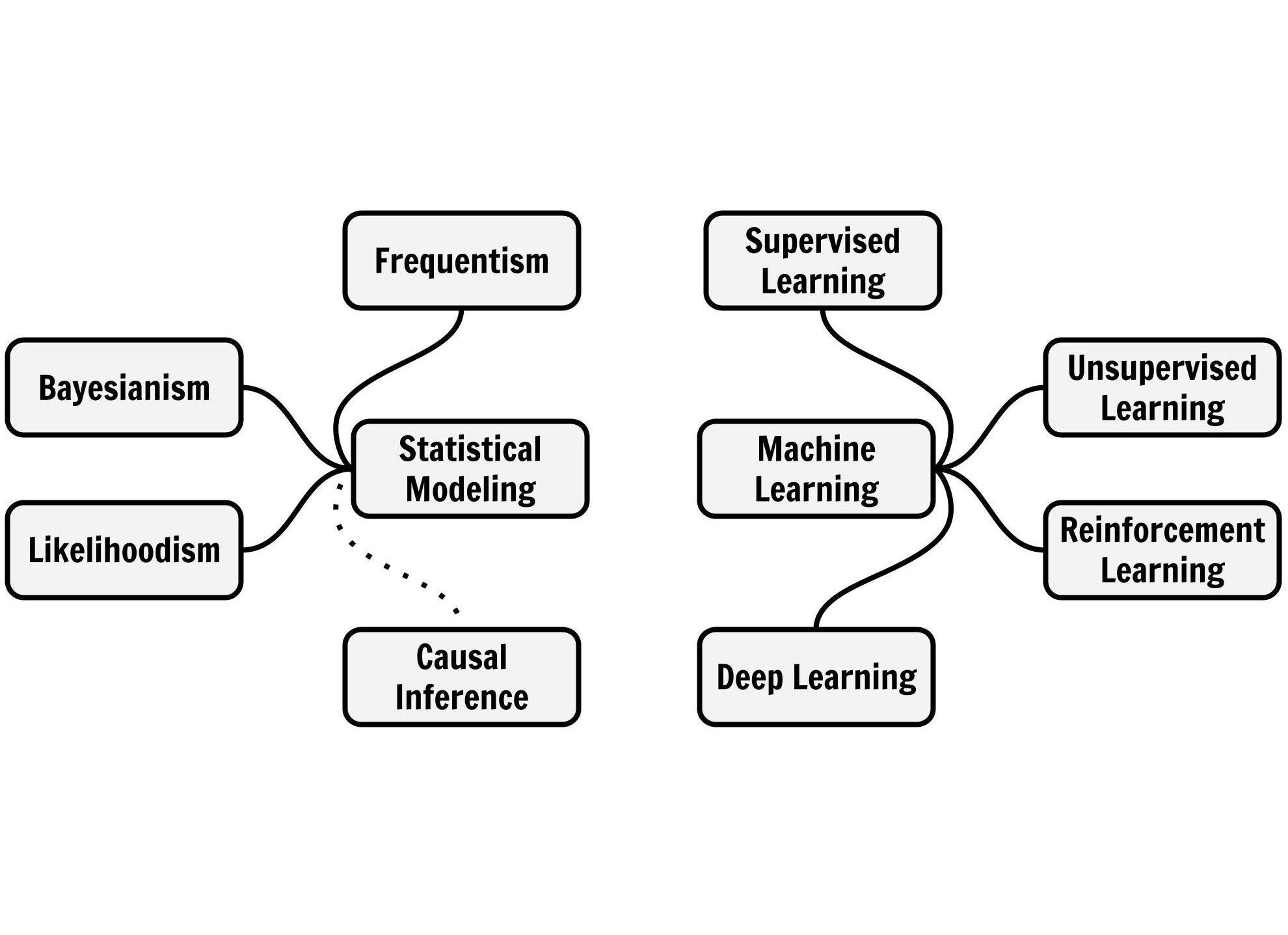
Breiman’s paper changed the way I think about modeling, coming from a more traditional statistics background. It was an eye-opener and ultimately my inspiration to write Modeling Mindsets: The Many Cultures Of Learning From Data.
The book differentiates more than just the two cultures — it also goes into the “flavors” of statistical inference and machine learning, like Bayesian inference and unsupervised machine learning.
If you have already read Modeling Mindsets, I would be immensely grateful if you could take a few moments to leave a review on Amazon. Your honest feedback not only supports my work but also helps other readers in their decision-making process.
