
to kaggle, or not to kaggle
Ultimately, it depends on Bob from IT Services.

You may have seen conflicting views on machine learning competitions (like Kaggle):
Kaggle is a playground and has little to do with reality
Kaggle produces the best of the best in machine learning
I’m exaggerating the positions a bit, but not too much.
So, which one is it? Playground or proving ground? I’d say both are right. But in different scenarios.
A tale of two modelers.
Modeling from scratch
You accept a new job offer at a company selling construction tools, joining a newly minted “data science” team. Well, it’s you and a junior data scientist. Your team is supposed to provide data-driven tools for decision-making within the company. After long months, you carve out a use case with the marketing team to help them with customer relations.
After many more months, you’ve finally convinced Bob from IT services to give you access to the data, found common grounds with the marketing department, and uncovered the meaning behind the data column “SLOPSLOP”.
You build a churn prediction model that helps the team take action to keep customers. On one hand, it’s “just” a simple logistic regression model, but on the other, it’s the first time the marketing team has an automated and scalable tool to detect customers who are about to leave. Before your model, churn was either ignored or actions were taken based on gut feeling and ego.
You just finished the workshop where you taught the marketing team to work with the newly built churn dashboard. Now you are low on energy and listen to your favorite AI podcast. It’s a discussion with a Kaggle grandmaster. Entertaining. Your thoughts wander to the churn model: at some point, you want to try out random forests. Should be like a day of work. But then you think of the emotional labor involved in bringing the marketing team on board if you can convince them at all. Anyway. For now, patience is required — it’s not even clear yet if the marketing team will use the current tool at all.
Improving a well-oiled machine
You accept a new job offer at a company producing screws. Your onboarding is fully automated with videos, checklists, and milestones. You join the quality control team. The first assignment: Improve the image classifier that’s used to identify defects in screws. Everything is version-controlled, documented, and continuously integrated. Your predecessor has done a fine job with the initial model. Still, they missed a few things: make use of data augmentation, better architectures, and a few other tricks you have up your sleeve thanks to your extensive experience participating in many machine learning competitions.
You managed to improve both precision and recall by a few points. Given the scale of the application, this translates into substantial time savings and increases the overall quality and trust in the products.
Unfortunately, not all your time can be spent modeling. Even if your friend thinks so (he’s a data scientist at a construction tool company and loves complaining about how old-fashioned his place is). You attend annoying meetings, get occasional data requests from other departments, and you have to code tools for data labeling. But still, you are grateful that your company has all its processes digitalized and understands the value of analytics and machine learning. This allows you to implement new high-leverage models with a high probability of being used and improve the many ML models already in place.
to kaggle, or not to kaggle
Whether ML competitions are essential or just a playground depends on how much of the daily tasks are similar to Kaggle-style work. The overlap can be quite substantial (well-oiled machine scenario) but modeling may also be just a tiny part and then a competition-style focus on model improvements is a luxury.
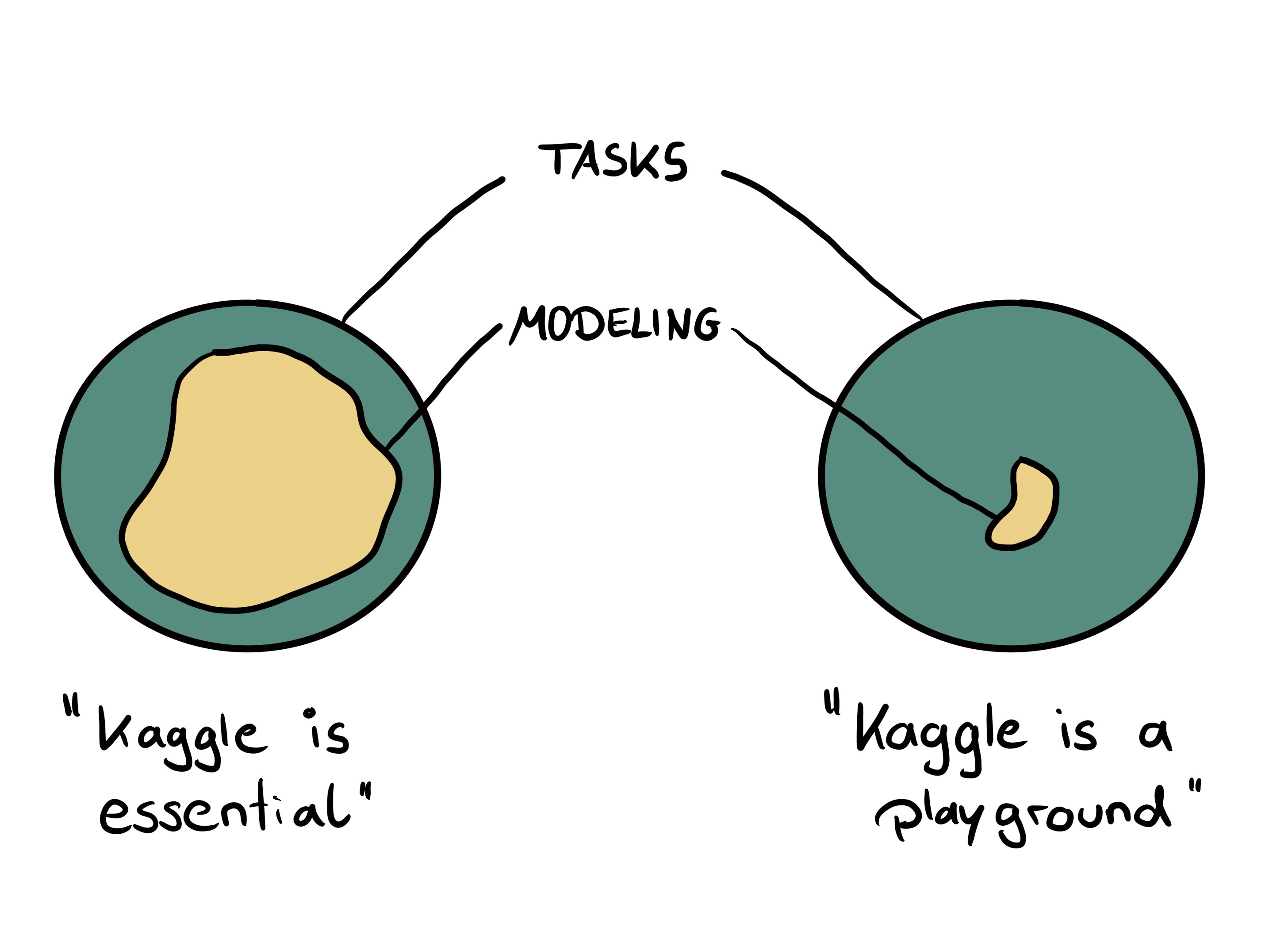
I would still say that for both scenarios it’s beneficial to participate in Kaggle competitions. As I explain in my book Modeling Mindsets, machine learning competitions are the best way to teach the core ideas of supervised machine learning.
However, how much you focus on competition should depend on the scenario you find yourself in as a modeler.
I got my start with Kaggle and I have a soft spot for it (plus two t-shirts, a mug and $500). However, although it's a great way to hone core ML skills, Kaggle competitions have 3 big weaknesses as a training curriculum. You address one here, which I'll call "building infrastructure", where infrastructure in this case includes code, hardware and perhaps most importantly people.
However, in my experience [admittedly a bit dated at this point] there are also two areas where Kaggle can encourage blind spots: data and metrics. Coming out of a diet of Kaggle competitions can leave you with the idea that data is something that just exists. If you're lucky–like in Kaggle–someone just hands it to you. But if not you just need to shake it out of Bob. However, often this is not how things work: maybe the data doesn't exist. Or if it does, it's poor quality, there isn't enough of it, it has the wrong fields, etc, etc. It's not uncommon that the best thing you can do to improve your model is go get more or better data.
Metrics are another area where Kaggle can give you an oversimplified view of the world. It does expose you to a number of different metrics, which is helpful. But since you are handed the final evaluation metric you never have to think about how you are going to evaluate your model. In my experience, this can be one of the trickier parts of the modeling process.
Which isn't to say Kaggle is bad, it's great at what it is, but it only trains you a portion of the modeling process.
Thanks for the insight here. I get a lot of questions regarding whether or not those new to ML should Kaggle.