
When trees still beat tabular foundation models

As you might have noticed, I’m rather optimistic about tabular foundation models. And while TFMs have been gaining momentum, beating benchmark after benchmark, they don’t outperform every time. And it’s not just random tasks here and there, but there is a pattern to it: there are certain characteristics of datasets where gradient-boosted trees outperform tabular foundation models, and there is even a small cluster where tuned neural networks take the trophy.
TabBench for classification tasks
We take a look at the TabBench V2 benchmark, which evaluates ML algorithms on 189 classification tasks. These classification tasks range from one hundred up to 150k rows, from binary to up to 100 classes, and from 2 to 1777 features. All datasets are IID classification datasets from OpenML. The company behind TabBench V2 is NeuralkAI, based in Paris, France.
TabBench compares three “clusters” of ML algorithms: tabular foundation models (TFMs), gradient boosted decision trees (GBDTs) like CatBoost, and tuned neural networks (NNs) like TabM.
Overall win rate of state-of-the-art (=2nd generation) Tabular Foundation Models: ~83% (caveat: based on accuracy; but TFMs are highly performant under the other metrics like F1 as well). The list of 2nd-generation TFMs includes TabICLv2, TabPFN-3.0, and Seldon.
Further down on the benchmarks website, there is a quite interesting figure, which drills down performance based on dataset characteristics.
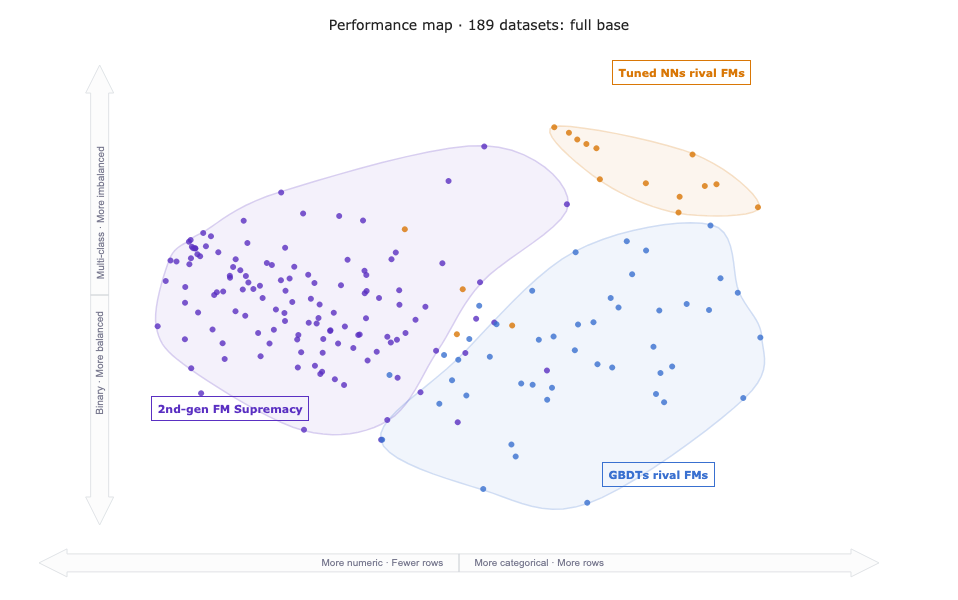
As far as I understand, the axes are the first two PCA components of the datasets × model-metric rank matrix. The x-axis goes from small tasks with mostly numerical features to categorical-feature-heavy, large tasks; the y-axis goes from binary, balanced tasks to multi-class, imbalanced tasks.
Three distinct clusters emerge, which give us a rough idea of when to expect which ML algorithm to work well.
When does which ML algorithm perform well?
Based on that same data, the creators of TabBench also provide a decision tree (I assume they trained it on the results), which gives us a good rule of thumb when to expect which ML algorithm to perform the best classifications:
Small to midsize (<44k rows) classification dataset with few categorical features (<15%) → Use Tabular Foundation Models (2nd-gen)
Smallish datasets with many categorical features → Use boosted trees
Larger binary datasets (>44k rows) → Use boosted trees
Large multi-class or unbalanced dataset → Use tuned neural networks
These are, of course, just tendencies and not physical laws. Your task may be balanced, binary classification, and your best model might be a neural network, or even a logistic regression model. By the way, logistic regression was not part of the benchmark, which would have been interesting to see as a baseline. Current baseline is ensembled xgboost. Another caveat: The benchmark only goes up to 150k rows, so beyond that, we can only guess. My guess, though, is that beyond 150k rows, tabular foundation models will not (yet?) take home too many prizes.
Where does that leave tabular foundation models? This snapshot supports the view that tabular foundation models are state-of-the-art models that stand side-by-side with boosted trees and tuned neural networks. However, the development of TFMs still has a lot of momentum. Go back to December 2025, and the recommendation would have been something like: use tabular foundation models only for very small datasets. Since then, they have been eating into the boosted tree territory improvement by improvement. The question is: how far will the TFM territory expand? I’m very curious to see how the TFM field will further develop, and, of course, will share with you what I learn along the way.
In the meantime, I encourage you to take a look at the TabBench V2 results and play around with the interactive figures; the site contains many more insights than I covered here.
If you want to learn more about Tabular Foundation Models, have a look at the open book I am working on: tabularfoundationmodels.com.
Hi Chris,
Do you know a toy example for which a tree model beats TabPFN
Regards
thank you! i would love to see win cluster but with additional feature engineering like from https://arxiv.org/pdf/2606.02384