

The Random Forest is not a Random Forest
The Random Forest is not a Random Forest

When you train a Random Forest you don’t get a Random Forest. You get Bagged Trees — at least when using RandomForestRegressor in scikit-learn.
Bagged trees are like Random Forests but without the sampling mechanism for the features. The default value of the hyperparameter max_features makes all the difference: Per default, it’s max_features=1.0, meaning all features are considered for the tree splits, which turns the Random Forest algorithm into the Bagged Trees algorithm.
But, does it matter?
When we look at the Random Forest algorithm1, the entire matter is easily resolved: Setting max_features=1.0 is just one possible setting for this hyperparameter. So algorithm-wise, Bagged Trees are just a special case of Random Forests and we could leave it at that, although I still find it unintuitive that the default of Random Forests is Bagged Trees in RandomForestRegressor.
But there are also other blurry boundaries: The Random Forests are linked to nearest-neighbor methods and we can see them as a special case of gradient-boosted trees.
This ease with which you can turn one ML algorithm into another, just by changing one parameter points to something bigger: how useful is it to think in “categories” of ML algorithms? Do we need a more deconstructed view?
And when we move away from the Random Forest algorithm to the models they produce, it gets even more blurry. Let’s look at how strongly hyperparameters can affect the models that the Random Forest produces.
When the Random Forest produces purely additive models
Setting maxdepth=1 makes the Random Forest produce purely additive models. maxdepth=1 means that each tree only has one split and the resulting trees are called tree stumps. That means there are no interactions between the features. We can sort these tree stumps by feature, and for each feature, we can combine the splits into a step function.
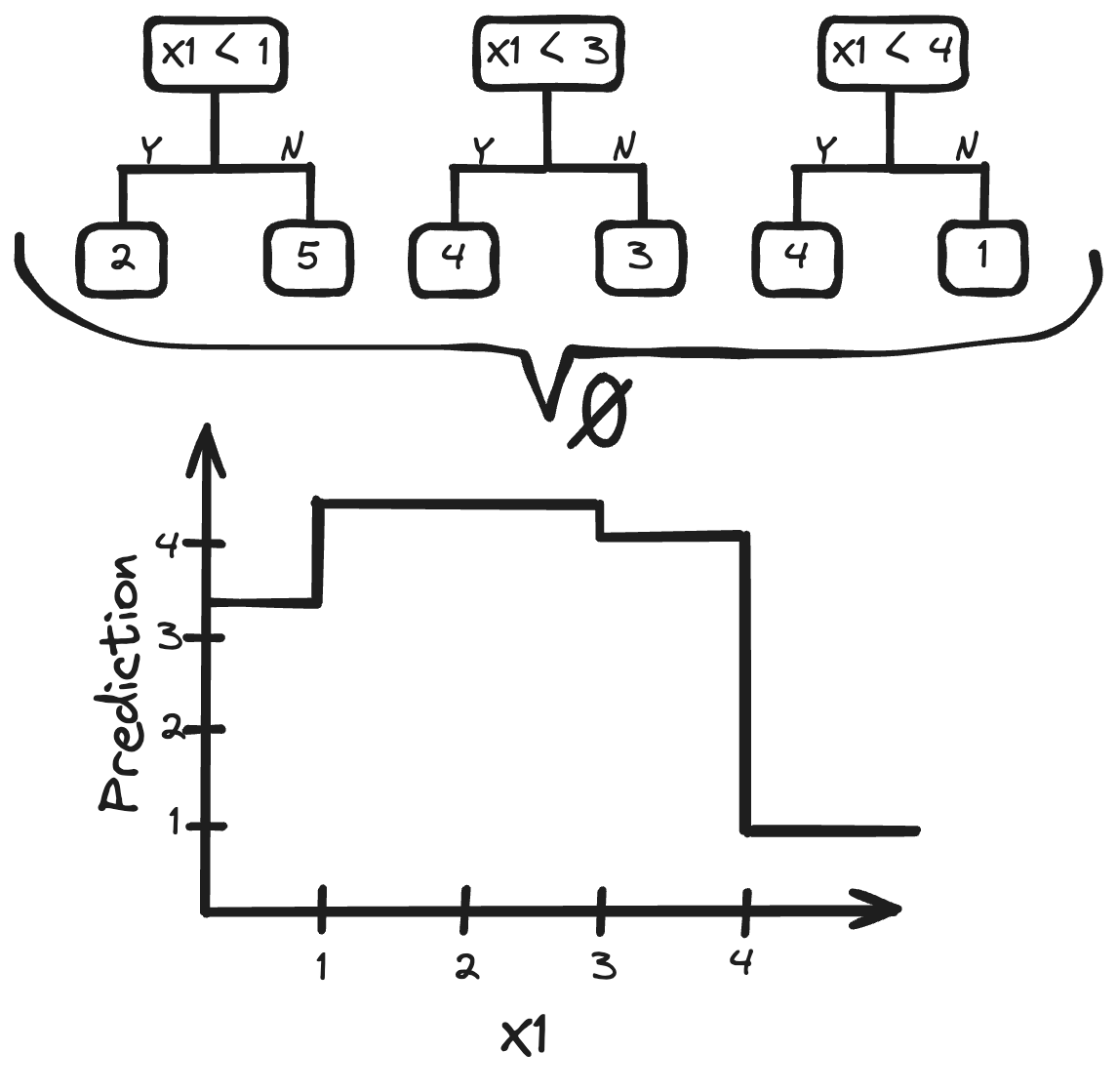
This means we can represent the model as an additive model:
Each f_k is the effect of the respective feature.
We might also get tree stumps and therefore an additive model in more indirect ways: Other parameters like min_samples_split or min_samples_leaf also indirectly control the depth of the tree. However, these parameters interact with the data size.
When the Random Forest produces a constant model
If you set min_samples_split or min_samples_leaf to a large value, the Random Forest regression returns simply the mean of the target as “model”. By the way, doing this via maxdepth=0 directly doesn’t work as it throws an error.
When the Random Forest produces a GAM with 2-way interactions
By setting maxdepth=2, we get a model with a maximum depth of 2, which means that at maximum two features can interact with each other. This results in a model with feature main effects plus two-way interactions. See also my post about functional decomposition of models:

The Random Forest always produces a decision tree
You can merge two trees by appending the second decision tree to each of the leaf nodes of the first. Then you can take the merged tree and merge it with a third tree in the same way. And of course, continue with even more trees. Long story short, you can take your trees produced by the Random Forest and turn them into a single, absolutely impractical, and inflated decision tree. There is absolutely no reason to create such a monster tree, except as a thought experiment.
You could even convert this monster of a tree into a decision rule list by turning the paths to each leave node into a decision rule. So technically it wouldn’t be wrong to say that the Random Forest is a way to train monstrous trees and decision lists.
It’s a matter of representation: We typically represent the model produced by a Random Forest as an ensemble of individual trees, both in terms of implementation and how we teach and think about it. But we can also represent it as a single tree or decision rule list.
There is a lot of ambiguity as to what a Random Forest model is. The breadth of models that a Random Forest algorithm can produce is surprisingly large.
So What?
Over the last weeks, I’ve thought a lot about inductive biases and wrote a mini-series about it:

A way out of this ambiguity is to think of machine learning algorithms not as fixed categories, but as sets of inductive biases. Hyperparameters can impact inductive biases as strongly as changing the ML algorithm. But we typically learn about ML algorithms in categories: This is the Random Forest, here we have the SVM, this is k-means, and have you met ResNet?
As an experiment, I’m working on a different way of talking about machine learning: In a deconstructed way, where we look at the building blocks. This means first separating machine learning into representation, optimization, and evaluation (based on this paper). And then go even further and examine the building blocks of representation, optimization, and evaluation. By taking machine learning apart, we understand ML better and become more creative modelers. This is the approach I take in my latest book project “Reconstructing Machine Learning” which I just started.
If you are interested in this book, you can sign up for updates:
“Random Forests” can refer to two things: The machine learning algorithm itself, or the model produced by it. In this post, I use Random Forests to refer to the algorithm.
Great post, got me thinking and taking various notes. Thank you for sharing!
Tow feedback points:
The current default for max_features is sqrt, but yes, it used to be auto. https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
I think the post could benefit from a more obvious explaination of what that max_features hyperparameter actually does.