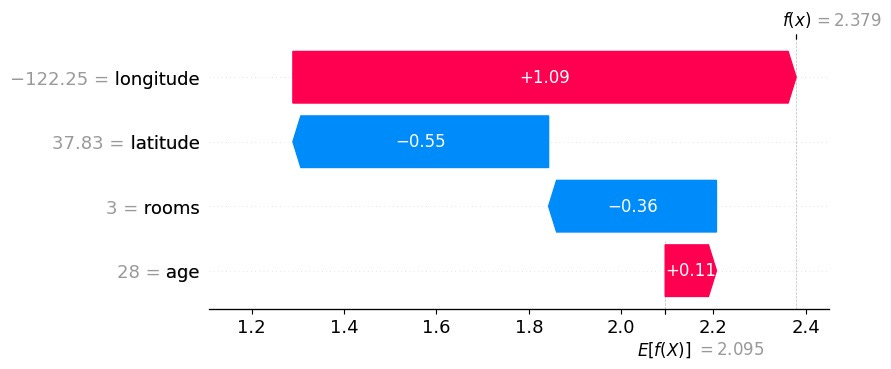
SHAP is a method from explainable AI. The method can be applied to machine learning models to attribute the model predictions to the individual features.
Typical SHAP plot where the prediction of 2.379 (minus the expected prediction of 2.095) is attributed to the individual features. Here, for example, +1.09 is the SHAP value for longitude.
The shap package implements more than 10 estimation methods!
If you already know SHAP, like from my book Interpretable Machine Learning, the original SHAP paper, or various block posts, you might know Kernel SHAP. But the Kernel estimation method already belongs in a museum. While it’s still available in the shap package, it’s no longer the default.
This post gives you an overview of different SHAP estimators and which are actually used instead of Kernel SHAP.
A quick reminder why we have to estimate SHAP values: SHAP values are computed based on coalitions: How much do features contribute to other sets of features for the prediction? For the exact SHAP value, all coalitions have to be tried out. But in machine learning, there are often too many features, and thus too many coalitions. Therefore SHAP is only approximately computed. Furthermore, to simulate that features are absent from a coalition, SHAP uses Monte Carlo integration.
Exact explainer: compute all coalitions
This estimation technique iterates through all possible coalitions. That’s 2^p coalitions in total. But it’s still an estimate of SHAP values since the data used for simulating feature absence is a sample.
Sampling explainer
Turns out that you don’t need to iterate through all possible coalitions of features. It’s enough to sample feature coalitions, which is the idea behind the sampling explainer.
Permutation explainer
SHAP values can be defined via coalitions, but another option is to define permutations of features. That’s the idea behind the permutation explainer. Each permutation is then iterated through to create coalitions.
Kernel explainer
The kernel explainer is the one that came with the original SHAP paper. The idea behind this estimation method is to sample coalitions and have a binary representation vector for each coalition (1 if the feature is in the coalition, 0 if not) and then fit a linear regression model with a certain weighting that ensures that the result will be SHAP values.
Partition explainer
The partition explainer is a model-agnostic estimator based on a hierarchical tree for the features that tell the partition explainer how to recursively compute the SHAP values. The Partition explainer is useful when the features are text or image inputs, but also when features are correlated.
Linear explainer
For linear regression models, the SHAP values follow a simple formula, based on the coefficients of the linear regression model:
Similar to the linear explainer, the additive explainer makes use of the structure of the model so that the SHAP values can be expressed as a function of the model component for the respective feature.
The tree explainer works for all tree-based models such as decision trees, random forests, and gradient-boosted trees models like xgboost. The tree-based structure allows a more efficient estimation of SHAP values by iterating through the tree paths and keeping track of the coalitions for each split.
Gradient explainer
Computes the output’s gradient with respect to inputs. As the name says, it’s gradient-based, so it only works for models where you can compute the gradient of the loss function with respect to the inputs. Like in most neural networks. The gradient explainer is inspired by the method called Input Gradient.
Deep explainer
Backpropagates SHAP value through network layers (inspired by DeepLIFT). This explainer starts with the difference in predicted value and average prediction and then backpropagates it through the neural network. So it’s a method that is specific to neural networks. It implements rules on how to backpropagate it based on which layer we are passing through.
The estimation methods that matter
Not all estimation methods are actually used. If you use the shap package without specifying an explainer, the default is method=‘auto’ which picks the best method automatically. Better means faster or more accurate. Roughly that means:
Exact explainer for models for tabular data with few features (<15)
Permutation explainer for larger tabular datasets
Partition explainer for images and text data
Linear, Additive, and Tree explainers whenever possible