
A simple recipe for model error analysis

Error analysis is a powerful tool in machine learning that we don’t talk about enough.
Every prediction model makes errors. The idea of error analysis is to analyze the pointwise errors and identify error patterns. If you find error patterns, it can help improve and debug the model and better understand uncertainty.
Error analysis recipe
The reason that people don’t talk much about error analysis is probably because it’s so simple. You need a trained model, test data, and a loss function, and follow these steps:
Get model predictions for the test data
Compute the pointwise errors between ground truth and test predictions
You now have a dataset with features and errors
Aggregate and visualize the errors.
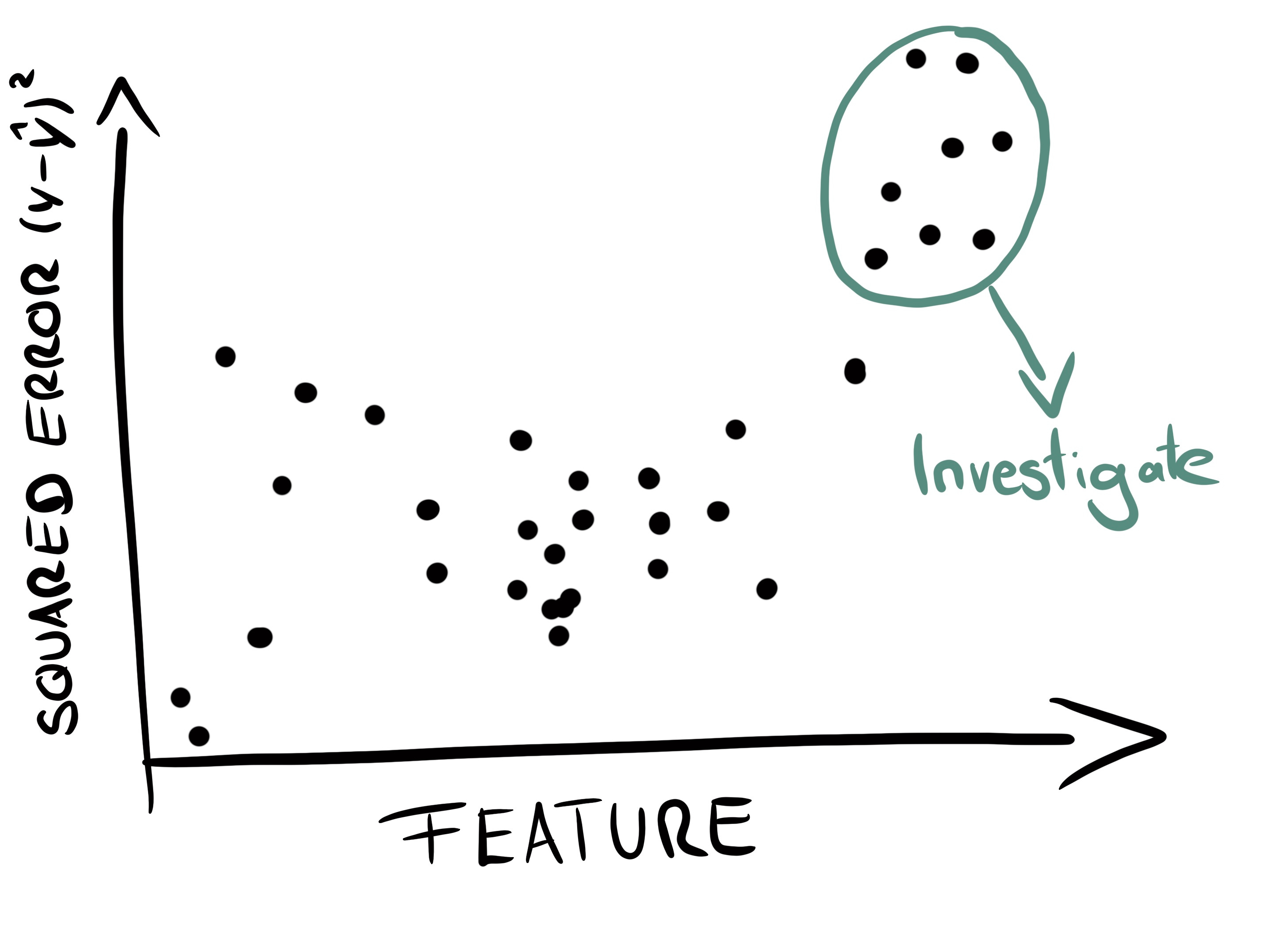
For example, you can create a scatterplot with a feature on the x-axis and the errors on the y-axis.
If you have a spatial prediction task, you can look for regional patterns.
For temporal tasks, you can look at how errors evolve over time.
Detect error patterns. For example, you can fit another interpretable model, such as a decision tree, to predict the errors from the features and interpret the tree structure.
Identify the reason why some errors are larger than others. Reasons can be inherent uncertainty, problems with data collection, small sample sizes, missing data, problems with feature engineering, etc.
Potentially fix the source of errors.
The loss function must be computed pointwise, like the squared error instead of the mean squared error. Or at least it needs to be computable for arbitrary groups of data.
This recipe is a very simplified version. In a real project, you may have multiple performance metrics, you might have a complicated validation setup where you have to integrate the error analysis (cause you don’t want to touch the final test data), you may have a large number of features to look at, and so on. Especially step 6, identifying the source of errors, requires a detective’s mind, and you need access to both domain expertise and ML expertise to figure out what’s going on.
Many names for error analysis
Another reason that error analysis isn’t more of a “thing” may be that it goes by many names and there are many overlapping approaches:
In classic statistical modeling, there is residual analysis. Residual analysis also looks at the model errors (the residuals) but has a different goal: to check whether the model assumptions hold. For example, whether the errors follow a Gaussian distribution (for the linear regression model).
Sometimes practitioners use performance analysis which is error analysis with a flipped sign.
Sometimes error analysis falls under the umbrella of model debugging
Sensitivity analysis is also a way in which you could frame error analysis.
Ablation studies attribute changes in overall performance to changes in the modeling setup, rather than breaking down the error by data points or groups.
Outlier detection and anomaly analysis focus more on extreme or rare data points.
I recommend using error analysis in every machine learning project. I’ve successfully used it to identify feature engineering problems with a water supply forecasting model. But I have to admit that I haven’t always used error analysis myself. So one purpose of this post is to remind myself to use error analysis in all of my ML projects.
You might want to check out this library (open sourced by my team at Datadome) that helps you find feature slices where your model underperforms https://github.com/DataDome/sliceline