
Causal Explanations: A Formal Way to Actually Understand Why
A guest post by David A. Kelly, Nathan Blake, and Hana Chockler (King’s College London)

This is a guest post by the Explainable AI / Interpretable ML researchers David A. Kelly, Nathan Blake, and Hana Chockler (King’s College London)
Do not all charms fly
At the mere touch of cold philosophy?
There was an awful rainbow once in heaven:
We know her woof, her texture; she is given
In the dull catalogue of common things.
Philosophy will clip an Angel's wings,
Conquer all mysteries by rule and line,
Empty the haunted air, and gnomed mine—
Unweave a rainbow, as it erewhile made
The tender-person'd Lamia melt into a shade
"Lamia" - John Keats (1820)
We may define a cause to be an object followed by another, and where, if the first object had not been, the second never had existed.
“An Enquiry Concerning Human Understanding” – David Hume (1748)
Humans tend to be suspicious of technology, even more so when this technology is complex and opaque. John Keats bemoaned the unweaving of the rainbow by Newton, that by explaining the nature of light, some magic and beauty had left the world. But our ignorance is not beautiful, and more recently, the likes of Feynman and Dawkins have argued that by understanding a thing, it becomes all the more wonderful. Then we can see the many layers underneath the world before our eyes.
Much of modern AI seems like magic, but here our ignorance is truly dangerous. We have already seen the dangers of social media, and are soon to discover what happens when we add to this generative AI. By understanding something about these black-box models, we can protect ourselves to a degree. But more than this, by understanding the model, it can enhance our understanding of whatever aspect of the world it has learned to represent.
Explanations with Actual Causality
Causal explanations are one way of achieving this understanding. In our implementation, called ReX (causal Responsibility eXplanations)1, we use a particular framework of causality called actual causality2. This is an extension and a generalisation of counterfactual causality defined by David Hume. Simply put, a part of the input is important if it has an influence on the outcome. An explanation in our setting is a part of the input that is, by itself, sufficient to get the outcome, when the model doesn’t see the rest of the input.
Ladybirds are beautiful insects. They are also quite distinctive: it is enough to see a part of a ladybird’s carapace to know it is a ladybird. One would hope that a model would use the same reasoning. Indeed, as we can see, a causal explanation, produced by ReX, of the “ladybird” label of this image is a part of the ladybird’s carapace.

Sometimes the results are more surprising. The image of a tennis player below is classified as “tennis racket”. This is actually quite reasonable as it shows a tennis player with a racket, playing tennis.

One of the possible explanations for the label, however, is a part of the player’s shorts. This is clearly not great: shorts are not a racket! This explanation, however, is very useful: it helps us understand where the model’s reasoning has gone awry and fix it.

Why would the model think that tennis player’s shorts are sufficient to classify an image as a racket? Well, there is a (small) number of possibilities here. First, maybe all images of tennis rackets it saw during the training were of tennis players, in traditional white tennis attire, with rackets. In this case, the fix would be to fine-tune the model by adding more images of tennis rackets without people.

Second, maybe all images of tennis players in the training set were captured during a game, with rackets in their hands. Then, the fix would be to add tennis players just standing there with hands in pockets or sitting on a plastic chair between the sets without their rackets. The point is, an explanation uncovers a subtle error in reasoning and helps us to fix it.
The algorithm behind ReX
How does the algorithm work? First of all, the bad news: the exact computation of causal explanations is intractable: it cannot be computed in polynomial time. Now the good news: we can efficiently compute pretty good approximations. We do it in two stages. First, we rank the parts of the input according to how strong their influence is on the output (we are obviously interested in parts that have a strong influence). Then, once we have the ranking, we find an explanation (greedily), by adding the high-ranked elements until we get a set that is sufficient for the classification. The greedy part is simple: just keep adding elements and asking the model “is it enough? Is it already a ladybird?”.
The ranking is more challenging. Again, the bad news is that the exact computation is intractable — by this time it shouldn’t surprise you: all interesting and useful things in causality are intractable. The good news is that we have an iterative refinement algorithm to compute a good approximation of the ranking.

Intuitively, a part of the image is the highest in the ranking if it, by itself, is sufficient for the classification. There can be several such parts! A part of the image is lower in the ranking if it is not sufficient by itself, but it is sufficient together with several other parts. A part is completely irrelevant if it is neither. We start with big parts (in the example we partition the image into four parts, randomly) and then refine the important parts iteratively.
The random partition obviously influences the ranking: if one of the parts is huge and another is tiny, it is likely that the huge part is deemed more important. We combat this by repeating the algorithm multiple times with different random partitions.
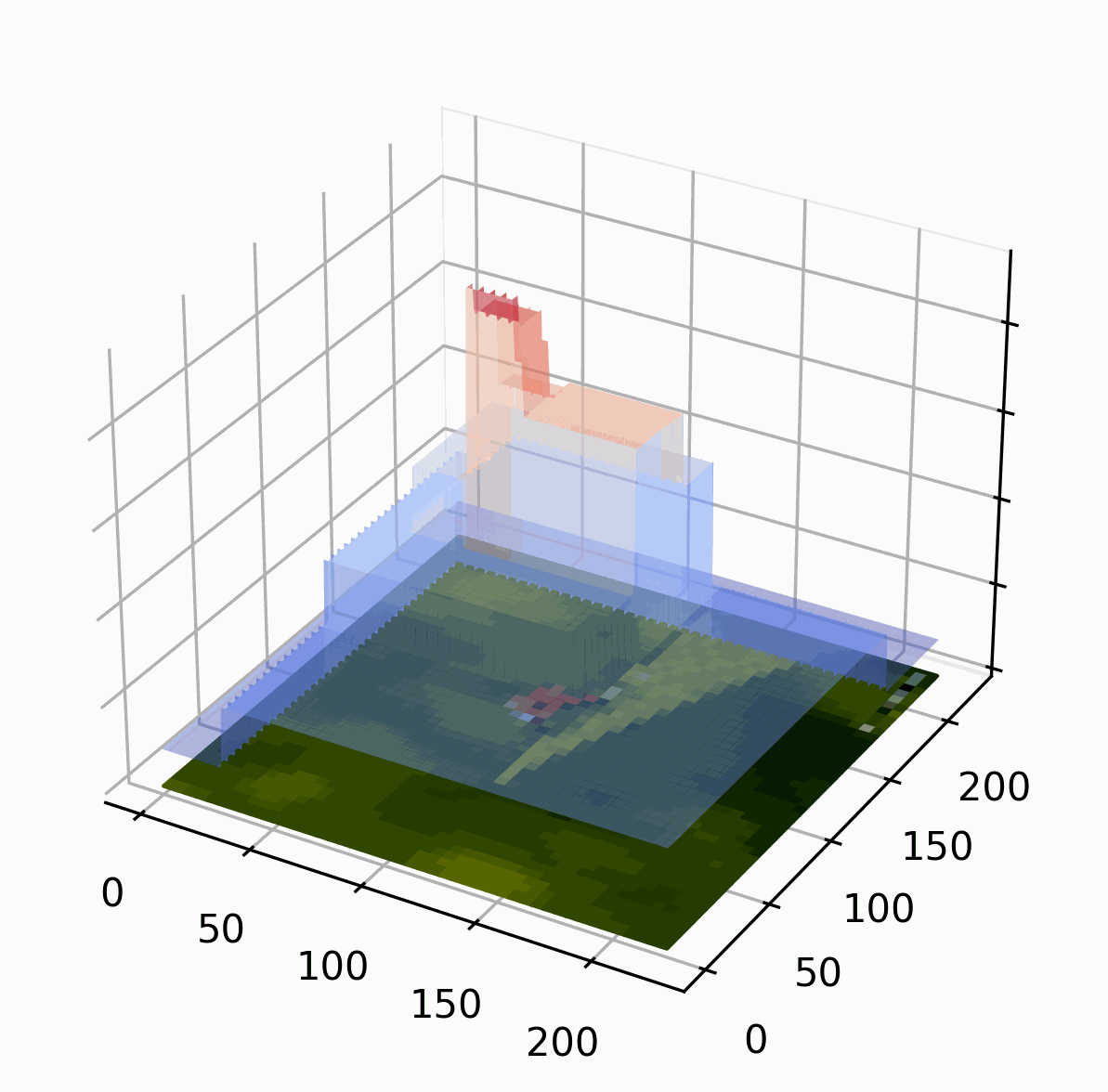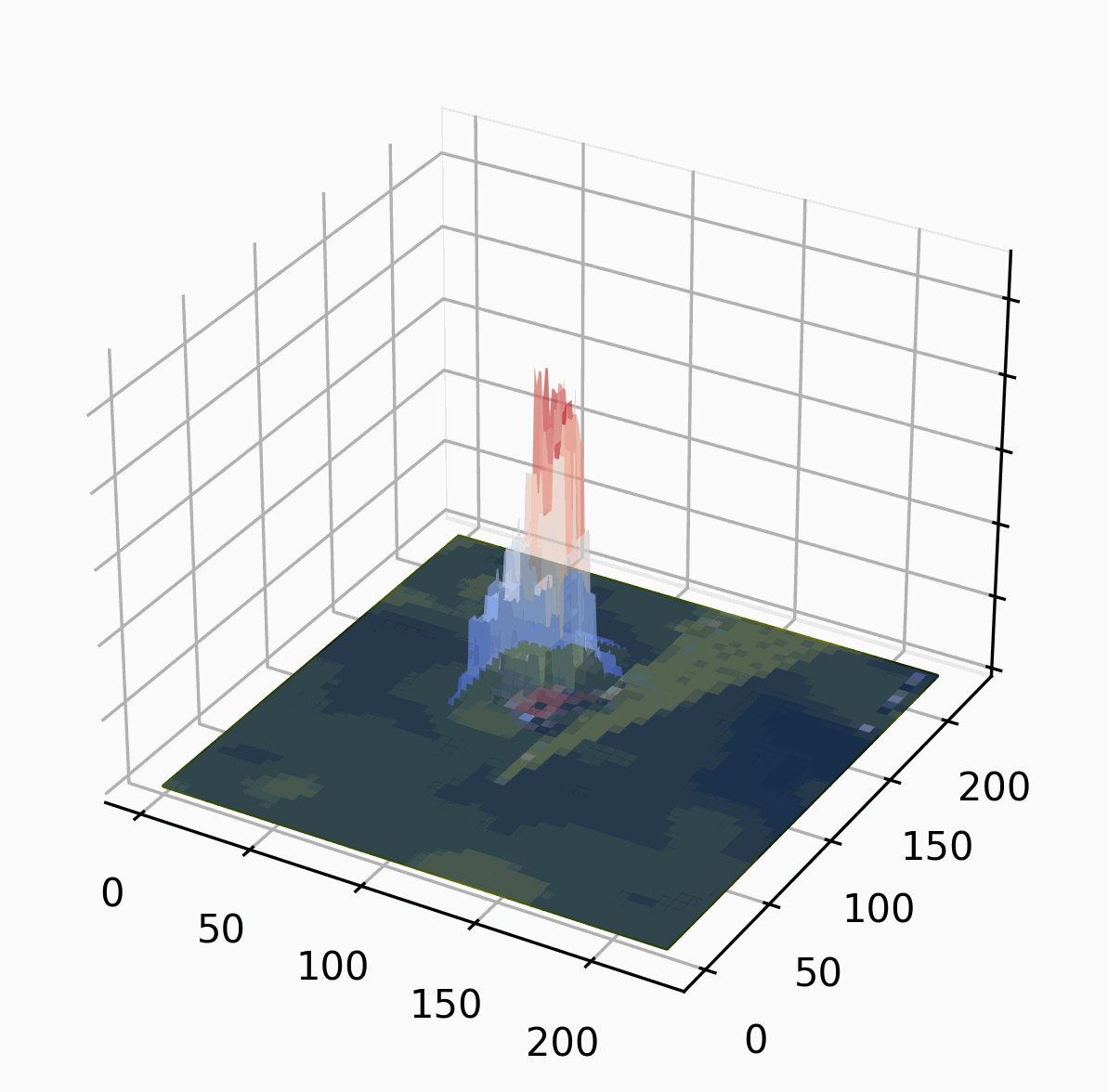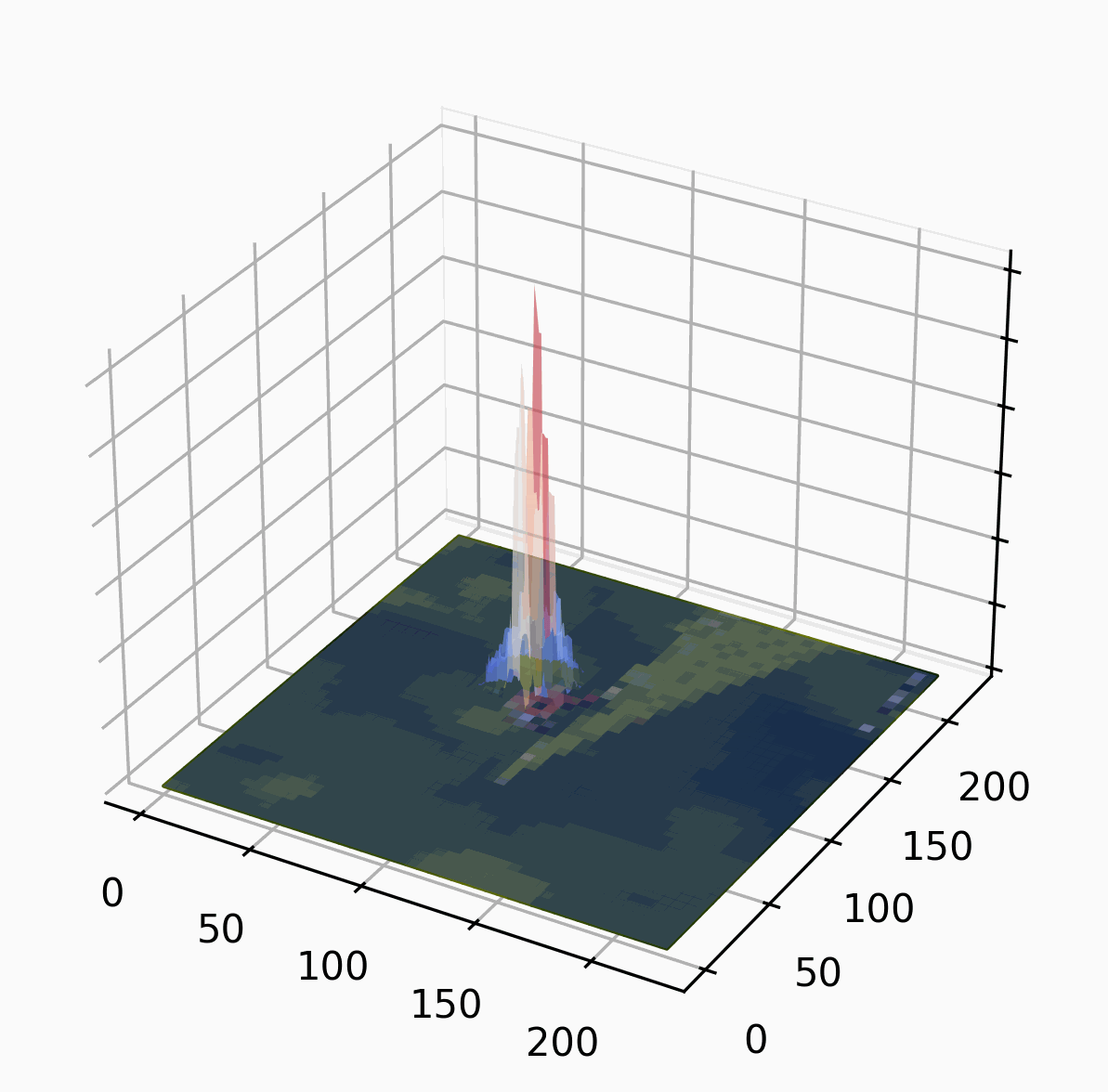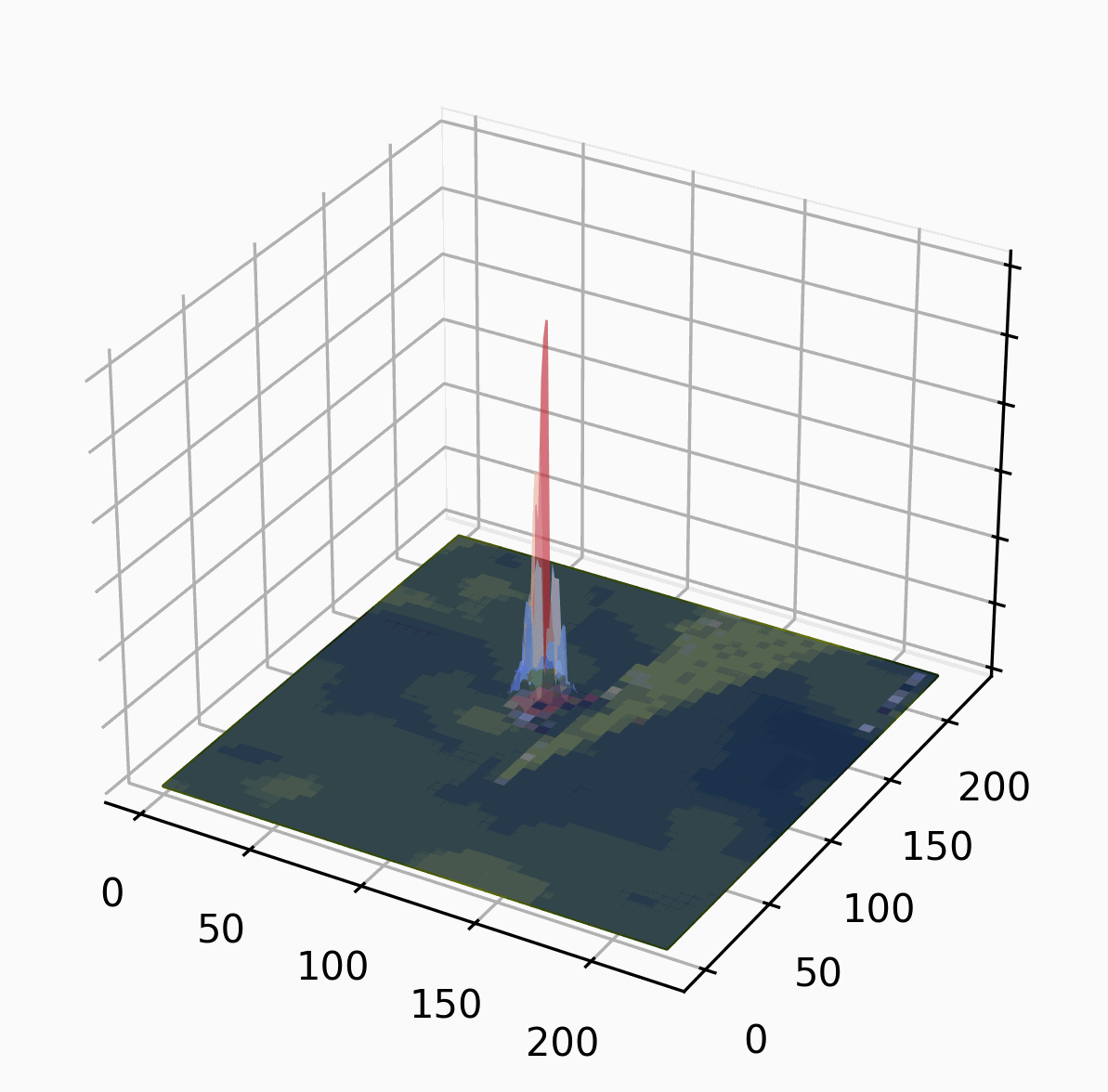
We use this responsibility landscape as the basis for generating explanations.
A sufficient explanation for a ladybird. Only the highlighted pixels are required for the ResNet50 model to give the label `ladybird’.
A sufficient explanation need not be unique. There can be multiple parts of a given image, each of which is sufficient on its own for the model to output the same label. In the image below, there are three explanations of a ladybird, with no pixel overlap and (in this case) at least 30% of the original confidence of the model. ReX can search for any number of explanations with the degree of confidence and overlap being anything the user wants.

ReX is under active development. If you want to stay abreast of changes (or even suggest some) then you can find the code here: https://github.com/ReX-XAI/ReX . We also have a stable version on pypi which you can install via pip: https://pypi.org/project/rex-xai/ .
We would love your feedback!

ReX is primarily an image classification explainer, but we are also extending it to work on tabular data (see this notebook) and even 3D data.
It has a powerful command line implementation and a user-friendly jupyter notebook api, though users can, of course, import the more complex code directly into theirs.
Parting Thoughts
We have entered the era of black boxes. To avoid being completely in the dark about their reasoning, we need explainability, and we need to formally define what we mean by explanations. This is exactly what we do with ReX.
"Causal Explanations for Image Classifiers" by Hana Chockler, David A. Kelly, Daniel Kroening, Youcheng Sun, https://arxiv.org/abs/2411.08875
"Actual Causality" by Joseph Y. Halpern, published by the MIT Press, 2019, https://mitpress.mit.edu/9780262537131/actual-causality/ .