As a technical book author in the field of machine learning, I often wonder how ChatGPT and other large language models can simplify my job.
Currently, I’m working on a book about Shapley values, and while I have completed a readable draft, it’s full of errors, poor sentence structure, and clutter.
Thanks for reading Mindful Modeler! Subscribe for free to receive new posts and support my work.
Proofreading my work is a tedious task, so I decided to try GPT-4. I’ve tried GPT-3 and GPT-3.5 before but with mixed results.
The Goal: get my book from a “bad draft” of the book to a good draft.
Phase 1: Experimentation with GPT-4 via ChatGPT
Time investment ~1h
At first, I used GPT-4 via ChatGPT, which required upgrading to a premium account1. I started with the following prompt:
You are an expert editor for technical books.
Text:
{text}
Provide a corrected version. One line per sentence.
And for the {text}, I inserted sections of my book. ChatGPT then returned a corrected version.
I was surprised by how well it worked from that simple prompt. But at a second glance, it wasn't what I wanted. Here are some problems I encountered with the output from ChatGPT:
Markdown reference [@molnar2018] was turned into a citation “Molnar (2018)”, but that should be done by markdown, not ChatGPT
Not 1 line per sentence
Edited output could be shorter
So I crafted the prompt until I was satisfied. This is what I ended up with:
You are an expert technical editor specializing in machine learning books written for machine learning engineers and data scientist. You are especially good at cutting clutter.
- Improve grammar and language
- fix errors
- cut clutter
- keep tone and voice
- don't change markdown syntax, e.g. keep [@reference]
- never cut jokes
- output 1 line per sentence (same as input)
My prompt crafting process was to start simple and add complexity as needed. Be specific about what you want. Seems to be, in general, the best way to work with LLMs.
But copy-pasting my entire book into ChatGPT … not an option. Fortunately, OpenAI also has an AI so I could automate the task with a short Python script.
Phase 2: Automation with GPT-4 via API
Time investment ~5 hours
Writing the Python script had a few hurdles but was not too much of a problem. I think it took me around 5 hours to write the script. How does it work?
The script takes a markdown file, splits it into multiple text pieces, combines it with the prompt, sends it via OpenAI API to GPT-4, and writes the results to a file.
You need an OpenAI API key and access to GPT-4, I think there’s still a waitlist. As an alternative, you can use GPT-3.5.
Some learnings while writing the script that cost me a bit of time to figure out:
OpenAI can be slow to respond, I had to increase the timeout time. Whether you will experience timeouts also depends on the number of tokens you send to OpenAI.
ChatGPT has a “system message” which you can use to instruct the LLM. In fact, I put my prompt into the “system message” and only put the text to edit in the regular message.
At first, I used the markdown text splitter from langchain, but it has a bug where it removes, e.g. “##”, which is annoying.
So I changed to the langchain tiktoken splitter, which was better but not perfect. It sometimes splits longer code examples.
Why split at all? Because the token window for GPT-4 is limited.
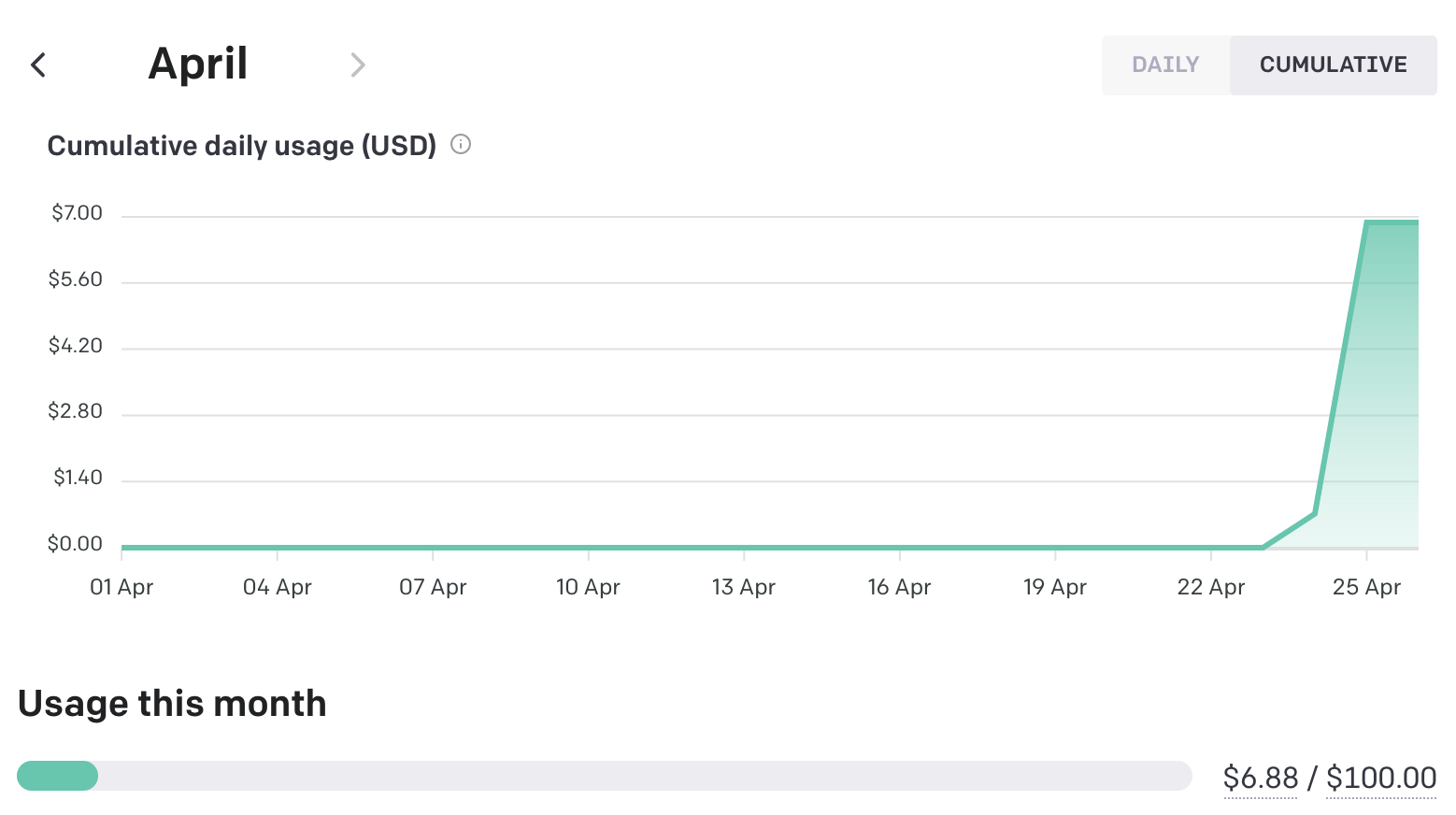
The Economics
The total cost for my book with 42 000 words was $6.88, which includes the OpenAI API costs for experimenting with the script and the prompt, but it doesn't include the experimentation with ChatGPT for which I also have Premium.
If you want a similar service from a professional proofreader, $6.88 won't bring you far. You will have to pay at least a couple of hundred dollars.
But is it even fair to compare the two?
My first subjective assessment: It's not as good as a professional proofreader, but it's not too far away. Given that I haven't done much yet with the prompt, I think there is room for improvement.
So I would say the GPT-editor is somewhere between Grammarly and a proofreader in terms of capabilities.
How Well it Worked
Overall, I was very satisfied with the results. Here are some examples of improvements:
Improving sloppy language:
Improving punctuation:
Cutting clutter:
All in all, it worked well for all the things I expected it to work well.
All the things that didn't work well had to do with lack of consistency across text snippets.
Some examples:
Inconsistencies in wording. Sometimes Shap was corrected to SHAP, sometimes left as Shap.
Inconsistencies in titles: Sometimes title case was used (words mostly starting with upper case) sometimes sentence case (which I used before)
These inconsistencies would be fixed by either larger context windows or by making them part of the prompt. One thing to give the model would be a kind of glossary that lists how things are named, and some decisions that otherwise might be treated differently across snippets like British versus American English, how to handle titles, …
The Workflow
This is how I incorporated the GPT4-editor script into my workflow. As a reminder, I started with a bad draft. Then, for each chapter (assume it's named chapter.qmd), I did the following:
Make sure the current version of a chapter.qmd is in version control
Run edit.py on a chapter
Check the changes with git diff --word-diff chapter.qmd
Make adjustments (rarely necessary). An option is to iterate through the lines with git using git add -p and then do git restore chapter.qmd to undo the not-staged changes.
Commit edited version
This workflow ensures that I catch errors and serves as quality control of the GPT-4 output. I also read the entire book afterward again, especially since I wanted to make sure I didn't overlook anything.
So, now I finally have a “good draft” of the Shapley values book.
By the way, if you are interested in being a beta reader, send an e-mail to readers@christophmolnar.com or just reply to this post. As a beta reader, you get early access to the book and can shape its outcome with your feedback.
The book’s working title is “Mastering Machine Learning Interpretation with Shapley Values: The Ultimate Guide to SHAP in Python”.
Caveats
Too much smoothing. Even though I "prompted against it", GPT-4 sometimes removed jokes or edgy language. This has the effect of taking the edges off but in an "every-text-will-look-the-same" type of way. For a rather technical book like the one about Shapley values, it's not that big of a deal, but for more opinionated books where language nuances matter more, this might not be ideal.
For books with “non-obvious” content and where language matters more, I think GPT-4 can still be of help, but the edits should be more conservative.
The stochastic nature of LLMs still peaks through. I had cases where, for most text snippets, it made the same decision (like whether to start bullet points with upper case), but sometimes made a different choice.
Next Steps
I’ll definitely re-use the GPT-editor script for my next book(s) as well. It's a clear use case of GPT-4, with clear outcomes that I can verify. It saves me a lot of time and stress.
The more I learn to work with it, the more specific I can make the prompt. So next time, I would add more stuff like whether the titles are in title case or sentence case, etc.
A possible future direction is also larger context windows, which would make other types of editing interesting.
This is great, however, your book’s content is now in the OpenAI database or corpus or training set or whatever you want to call it, even before being published. Aren’t you concerned about that? You have no copyright protection yet.






Nice post! You mention a edit.py script, which is not the script in the gist (that one is called gpt-proofread.py). Would you mind sharing that too?
This is great, however, your book’s content is now in the OpenAI database or corpus or training set or whatever you want to call it, even before being published. Aren’t you concerned about that? You have no copyright protection yet.