
The interpretability tax on tabular foundation models
Model-agnostic interpretability for tabular foundation models

Before “betting” on tabular foundation models, I made a similar bet on model-agnostic interpretable machine learning: I wrote two books and did a PhD. Model-agnostic interpretability fascinated me because of its potential “timelessness”. Since they work by studying the model predictions when manipulating the inputs, these methods should have a longer shelf-life than model-specific methods.
Tabular foundation models are a paradigm shift from training+predict to pretraining+ICL (in-context learning), making it a great test for model-agnostic interpretability tools.
Let’s dive in.
The remainder of this post is based on research from the paper Interpretable Machine Learning for TabPFN.1
Model-agnostic interpretation works out of the box for tabular foundation models
Consider this minimal workflow: You train a model, and then study its feature importance using permutation feature importance (PFI). PFI is a classic, post-hoc model-agnostic interpretability method. Meaning it works regardless of the underlying model structure. It only needs access to the .predict() function. Behind “.predict()” could even secretly be Bob from marketing filling that Excel based on gut feeling. If PFI works for Bob, it will work for TFMs, right? Indeed, it does work and looks and feels very familiar.
reg = TabICLRegressor()
reg.fit(X_train, y_train)
pfi = sklearn.inspection.permutation_importance(reg, X_test, y_test)The sklearn implementation of PFI computes R-squared for the test data, then shuffles each feature and checks R-squared again. The larger the drop, the more important that feature was. This is repeated for all features, typically averaged over a couple of such permutations, five by default.
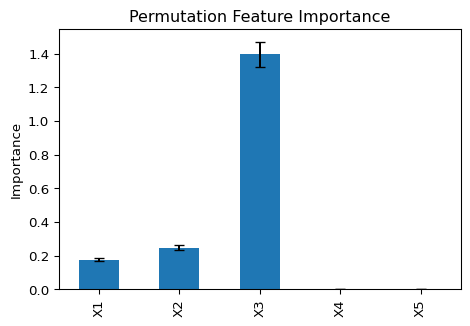
So far, so familiar.
If it weren’t for the changed costs.
Inference-cost inversion changes the economics of interpretability
On my MacBook Air M1, computing PFI took 104 seconds for this dataset of 1k rows (700 “training”, and 300 test data). Way more than a random forest would need.
The reason is that tabular foundation models are still slow. Not for training, but at prediction time. While traditional machine learning is training-expensive and inference-cheap, this relationship inverts for tabular foundation models: “Training” costs almost nothing, but predictions are expensive. Note that I’m excluding pre-training here, because I’m viewing it from an application perspective. Side note: While not a classic real training step, reg.fit() loads the TFM’s weights and pre-processes the “training” data, aka the context for in-context learning.
We could just ignore this cost inversion and throw more compute at our problem. Absence of training is neat anyway, and maybe we can just swallow the increased cost of inference. Certainly a possibility for the GPU-rich. But even then, the economics of interpretability are not so favorable. Permutation feature importance in the example above already requires 26x (1 + number of repetitions x number of features) times as many predictions as just predicting the test data. For an interpretability metric, you may only compute once. But if you start computing things like Shapley values along with every prediction, costs get out of hand quickly.
So what to do?
Better scaling for inference-heavy interpretability
We can speed up inference-heavy interpretability methods through TFM-friendly implementations. For traditionally trained models, it makes sense to chunk calls to the model: For PFI, you might call model.predict() with every new shuffling of the data. For TFMs, this no longer makes much sense. According to the paper “Interpretable Machine Learning for TabPFN”, the cost of inference per test data scales with O(ntrain^2/ntest), where ntrain is the size of the training data and ntest the size of the test data (in rows). So it’s better to bundle more test data into one call (if memory permits), because — relatively — it gets cheaper. I tested this out for computing PFI for one feature (computation time was averaged over 100x doing this). The naive version is two calls to the model, once with the original test data, once with the permuted. The batched version concatenates both before sending the data to the TFM for prediction.
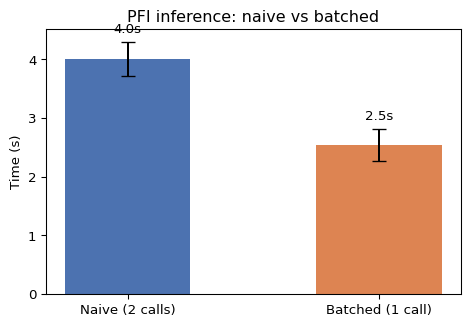
Efficiency for other methods like ICE, ALE, and PDP can also benefit from such implementation changes.
Adapting interpretability tools for a training-cheap, inference-expensive world
LOCO importance is a model-agnostic interpretability method that can also compute feature importances. It stands for “leave-one-covariate-out” and relies on re-training: Remove a feature from the training data, re-train the model, and compare performances on test data.
With traditional machine learning, LOCO is expensive when compared to PFI. To compute LOCO importance for an xgboost model with 100 features, you have to re-train the model 100 times.
This relation changes with TFMs as they are training-cheap and interpretability methods based on re-training become more attractive. Because under TFMs, LOCO costs roughly the same as PFI, due to the lack of a training step. “Re-training” under the TFM paradigm just becomes another forward pass of the data with one column removed.
For the following figure, I computed PFI and LOCO for one feature for both TabICL and a random forest, repeated 100 times, and measured how long it takes:
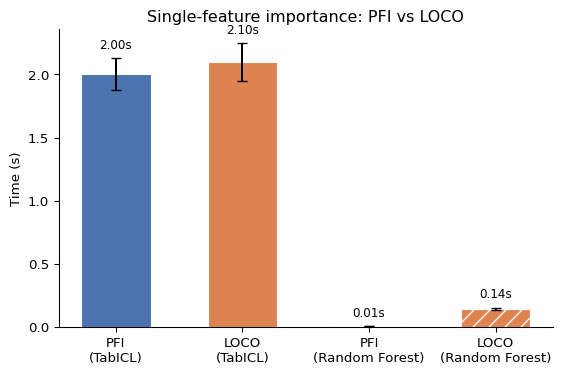
The random forest is, in total, much cheaper; however, note that no hyperparameter tuning is involved, so it’s not a 100% fair comparison. Look at the relation between PFI computation time versus LOCO computation time. For TabICL, it’s roughly the same, while for the random forest, LOCO is 10x more expensive compared to PFI.
Note that LOCO and PFI define feature importance differently. With PFI, we stick to a fixed model and see how it adapts to shuffling data. With LOCO, we ultimately compare two different models. When features are correlated, LOCO and PFI importances diverge and have different interpretations. These differences boil down to the question of whether our interpretation is true to the data (LOCO) or true to the model (PFI). Or, in a more cynical view, yet another case of correlation ruining interpretability.
Other interpretability methods, like Shapley values, also have re-training-based versions, which become more attractive in conjunction with TFMs. But again, with a changed interpretation.
So what?
All model-agnostic tools are still available for tabular foundation models, but the costs have shifted. We can adapt interpretability methods to some degree, e.g., by batch calling, or we might shift to more training-focused versions.
And, who knows, we might also see different types of interpretability arise:
Mechanistic interpretability for tabular foundation models.
Model-specific implementations. Think of TreeSHAP for tree-based models ( PFNshap?)
TFMs might enable new types of interpretability in the form of directly estimating properties of the underlying data.
I’m looking forward to seeing how interpretability for TFMs will evolve.
Rundel, David, et al. “Interpretable machine learning for TabPFN.” World Conference on Explainable Artificial Intelligence. Cham: Springer Nature Switzerland, 2024.
Loving the series Christoph. having a PFNshap would be a great addition to the interpretation toolkit
Is mechanistic interpretability at the same interpretable level as other methods which we use for classical models though?