

I currently work on the second edition of Modeling Mindsets. Self-supervised learning will be one of the additions to this new edition.
Self-supervised started as an auxiliary approach to supervised and unsupervised learning. The motivation: Labeled data is expensive, but we might have plenty of unlabeled data. Now we have to define some “pretext” task that learns a meaningful representation of the data that will help us with our classification task, like using word embeddings for sentiment analysis instead of n-grams.
How it works: Learning by reconstruction.
The idea: To create a prediction task even though there is no label, the modeler implements a procedure that automatically turns data into input-output pairs. For example, take an image (with color) and turn it into two images, the greyed version as input and the colorized version as output. Then train a model to reconstruct the data, hopefully learning a useful representation. In this case, the “reconstruction” is learning to colorize. Then the modeler can use this model to represent the data (as fancy feature engineering) or might even apply it directly, for example as an add-on in a photo editor software to colorize images.
But today’s image and role of self-supervised learning has shifted: Ask a layperson what AI is and you might hear about ChatGPT and other Generative AI tools. These are all based on self-supervised learning as well. So we have a broad range of goals with self-supervised learning from feature learning to asking for Lasagna recipes in the style of an Eminem song.
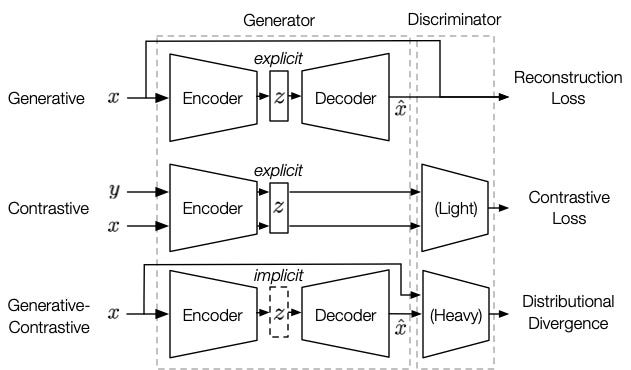
We can broadly categorize self-supervised approaches into contrastive, generative, and adversarial.
Generative modeling: Generative models first encode and then decode the data and can be used to generate new data. Thanks to Generative AI like ChatGPT and Midjourney, the generative approach is the most popular of the self-supervised paradigms.
Contrastive: For the contrastive approach, two or more inputs are compared. For example, using the triplet loss, one compares an "anchor" with a positive and a negative sample, the positive has the same label as the anchor. This approach is mostly used for representation learning and to be used in downstream tasks.
Adversarial: A mix of generative and contrastive. The most famous is the Generative Adversarial Network (GAN) to produce images.

Network architectures for generative, contrastive, and adversarial approaches to self-supervised learning. Image by Liu et. al 2021, CC-BY 4.0.
Chapter Sneak Peak
If you want to dive deeper into self-supervised learning, you can read a draft of the new chapter in Modeling Mindsets (and give feedback ):
The chapter is a quick high-level read and introduces the big ideas of self-supervised learning. Any feedback is welcome (you can directly comment inline).
Hi! Are you considering to make it available online, as you are doing for Interpretable ML? 🙂