
Use ML interpretability to gain data insights
A theory that extends model interpretation to the data-generating process

Next to justification and model improvements, data insights are one of the goals of ML model interpretation.
When I asked on Twitter, data insights was even the most important goal:

We have to distinguish two scenarios for data insights:
Explorative: You just want some general insights into which features are useful etc. If the insights turn out to be inaccurate, it’s not a big problem.
Inference: You have a specific question, such as how fertilizer affects crop yield, not only in the “model world”, but in reality. You want a reliable answer.
In statistical modeling, we have a similar distinction: Descriptive versus inductive statistics. Descriptive stats is a playground that allows you to describe data without making too many assumptions. Inductive statistics is serious business with lots of assumptions, a world full of hypothesis testing and statistical models, but which ultimately justifies making statements about the real world.
Scenario 1: Explorative
You start a new job as a data scientist in a field you know little about. Say hydrology. Using interpretable ML (e.g. permutation feature importance and SHAP) on a model that predicts the water supply of a dam, you get first insights about how useful the features are, how e.g. precipitation is connected with the supply, and so on. This is the explorative scenario: You can be creative and an erroneous interpretation won’t get you fired.
Scenario 2: Inference / Inductive
You build a novel prediction model together with a hydrologist. The hydrologist has a theory of how certain weather patterns are connected to the water supply in the long run. To describe the connection between the features and the prediction, you use ML interpretability methods and the outputs are reported in the paper. The burden on the interpretability output is high: You make conclusions about the real world. Even if you carefully address limitations in the paper, there is still the danger that some overeager journalist will extrapolate the findings to the real world for you. So you should better have that model interpretation on solid footing.
Towards inference via ML interpretability
Machine learning isn’t designed for making claims about the real world. Supervised ML is designed for making good predictions. To interpret the model and extend this interpretation to reality, we need a theory that links the two.
There is a good starting argument: A system that accurately predicts must have learned something about the data-generating process, assuming we have put some constraints on the model. Like making sure that it doesn’t learn bad shortcuts such as predicting that asthma patients are less likely to develop pneumonia (see this paper).
In classic statistical modeling, you typically make assumptions about the data-generating process, such as how the target is distributed given the features, how the target is linked to the features, and so on. Based on these assumptions you pick the right model and do inference. The way you design and pick models differs strongly from ML since statistical modeling is a different mindset altogether.
For ML it’s more difficult to have such a theoretical foundation. Especially when approaching ML as competition between models and the most performant model wins. What’s the theoretical argument that links an SVM to the real world? Even for “interpretable” models, like decision rules, how could you argue that this represents the data-generating process?
Time to advertise some research of mine 😁.
While it’s difficult to argue that the structure of a specific model class (SVM, xgboost, transformer) represents the data-generating process, we can argue that the model is a good representation of the mapping between features and the target of the data-generating process. This means we don’t care about how the model works inside, whether it relies on support vector or tree stumps, but we care about how well it approximates the true function Y=f(X). This view opens up a different approach to inference: We argued in a (more philosophical) paper that we can use model-agnostic interpretation to study the real world. This more technical paper studies the Partial Dependence Plot and Permutation Feature Importance. The rough argument: the model tries to model the “true” relationship between the target and features. Assuming there is a true relation, we can also apply, at least in theory and simulation the PDP on the true function. Then the question is: How do the real PDP and the model PDP differ, and when are we allowed to draw conclusions from the model PDP about the real PDP?
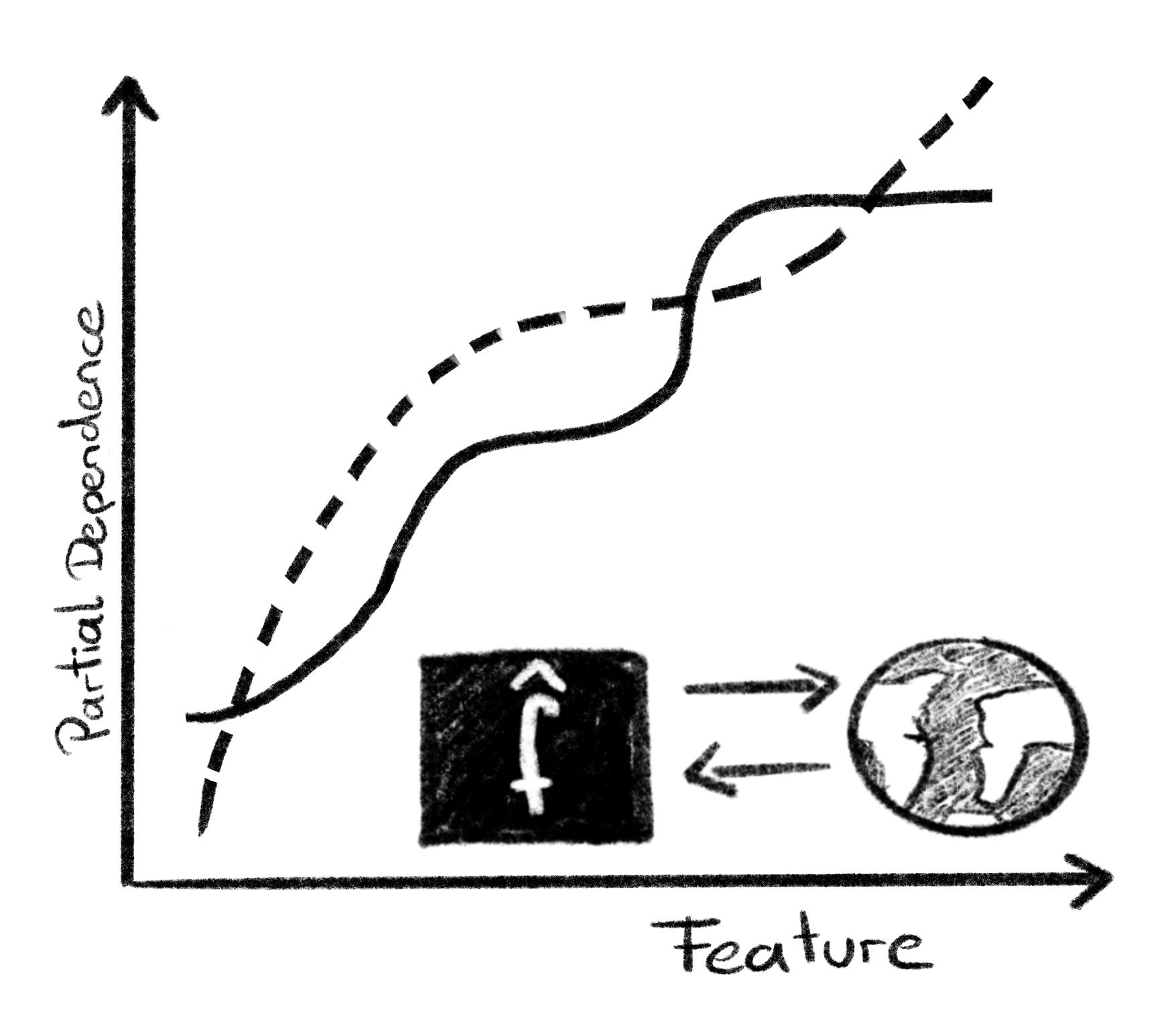
To summarize our findings in the paper: The PDPs differ because of model bias, model variance, and estimation error of the PDP. You can attempt to quantify the model variance and the estimation error. The model bias is a more difficult beast, but you can get rid of it by assuming that the model is unbiased, which is a strong assumption though. But it’s an argument for picking the best-performing model. This research is still quite early, so take it with a grain of salt.
To summarize, here’s my advice for using ML interpretability for data insights:
The model should be well trained. Good performance. Well calibrated. Interpreting a poorly trained model will give you unreliable data insights.
Closely align the model with domain expertise: Use meaningful features. Make sure the model doesn’t learn spurious shortcuts. Only rely on quality data.
If the data insights you seek are more explorative, ML interpretability is your playground: You can use any interpretability method. The better you know the limitations of each method, the more reliable the insights.
If you are seeking definite answers via ML model interpretation, things get tricky. A good bet is model-agnostic methods, but it’s still early research.
Next week, I’ll talk about using ML interpretability to justify the model. This is gonna be the broadest of goals, ranging from verifying alignment with domain knowledge, communicating general model behavior and individual predictions, and auditing the model.