
What is TabPFN's Thinking mode?

When I read the TabPFN-3 Technical Report, the benchmark for “TabPFN-3-Thinking” stood out: it appeared at the top of the TabArena benchmark for large datasets. TabPFN-3-Thinking also surpassed AutoGluon 1.5 extreme, an open-source AutoML framework that trains and ensembles many models — including foundation models like TabPFN, TabICL, and TabDPT. As we know, ensembles are typically the way to go in machine learning if you want to squeeze out the last bits of performance. And yet, the Thinking mode beat it:
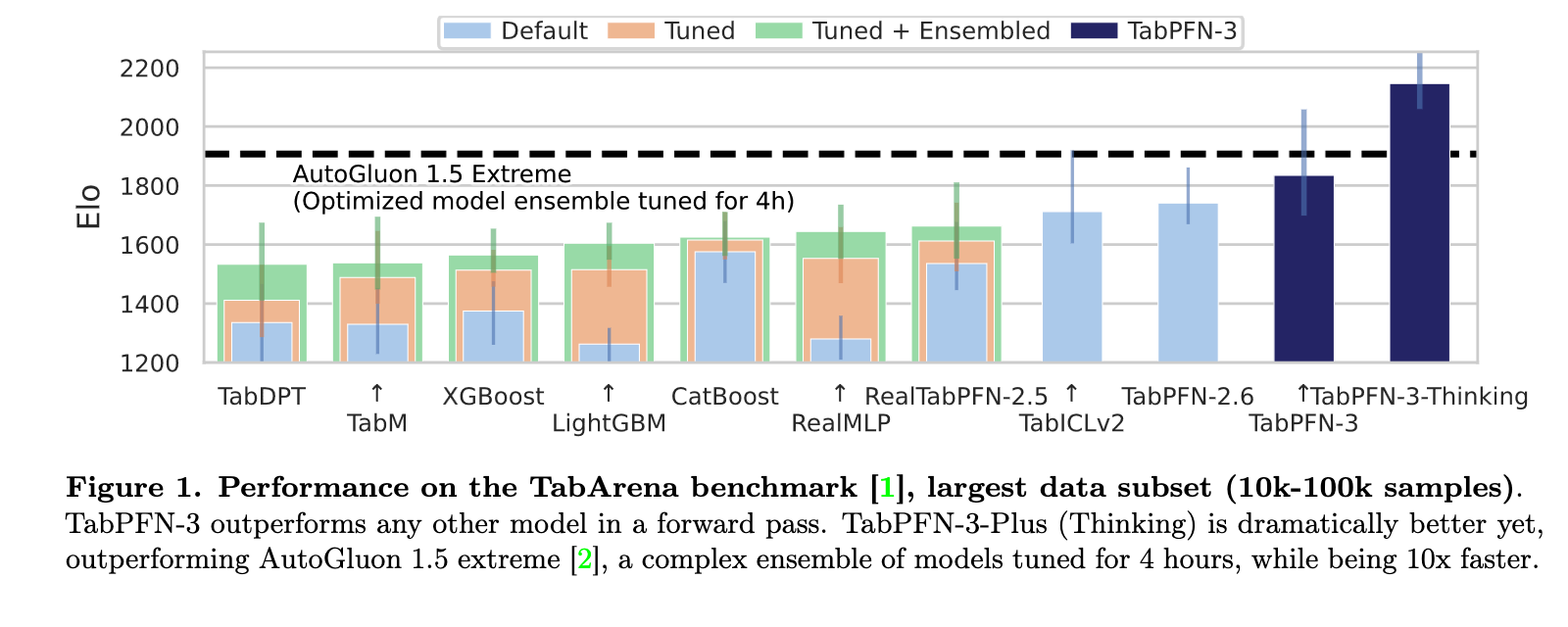
So, what is this mysterious Thinking mode?
Thinking mode is not open source
Not much is publicly known about this mysterious Thinking mode. It’s bundled into “TabPFN3-Plus,” the closed-source/commercial part of TabPFN. The technical report has only one paragraph on the Thinking mode and keeps things high-level. In general, Prior Labs has chosen a dual path: an open core with their model architecture being open source plus closed source parts, like the prior and the Thinking mode. This is a similar playbook to what open-core infrastructure companies like Red Hat and GitLab are doing. Give away the core for free, monetize some of the features, especially for enterprise.
What we know about Thinking mode
We have two sources available to go full detective. Let’s start with the TabPFN-3 Technical Report, which gives us the following hints:
Thinking is “test-time compute scaling” of TabPFN.
The authors also refer to the mode as applying “additional inference-time computation.”
It outperforms AutGluon 1.5 extreme in less than a tenth of the runtime.
No use of LLMS, real data, internet, or any other model besides TabPFN.
The performance gains seem to be mostly for large datasets.
A bit more information is provided in the TabPFN documentation:
The Thinking mode flag is set in
.fit(),not in.predict().The docs also state that the Thinking mode “fuels recurring predictions”.
There is a
thinking_effortparameter, which can be set to 'medium' or 'high'. This parameter steers the “effort & compute” of the Thinking mode.The
thinking_timeout_sparameter sets a time budget.A “
thinking_metric” parameter controls which target metric to optimize during Thinking mode. Currently supported metrics are: Accuracy, LogLoss, ROC AUC, RMSE, and MAE.There is a separate monthly quota for Thinking mode of 20 fits per month.
Alright, this is all I found. Everything that follows is speculation based solely on the limited publicly available information.
What Thinking mode is probably not
Even though not much is known, I would exclude some possibilities for Thinking mode based on the available information.
I don’t think it’s an ensemble with other models, since the report states that no other models were used. However, it might be an ensemble of TabPFN models.
It’s probably not some novel pretraining procedure, as TabPFN-3 with and without thinking seem to share the same pretraining.
No LLM chain-of-thought involved, as the report states no LLMs involved.
I don’t believe Thinking mode involves gradient-based fine-tuning of TabPFN, since the metrics the user can pick are not differentiable.
Let’s speculate
The TabArena results for plain tabular foundation models are quite strong. And yet, they “only” do in-context learning, which does not even change the model weights. Besides that, no particular optimization happens in vanilla TFMs. For example, TabPFN is already an ensemble, but the ensembling is agnostic of the underlying task: The variety between ensemble members comes from changing the feature order and the pre-processing pipeline. What I want to say: there is an opportunity to optimize beyond in-context learning.
In my opinion, there are strong hints that Thinking mode might involve some validation-driven search: there is some computational expense (up to 1/10th of the AutoGluon 1.5 extreme compute time); the budget parameters would be coherent with some type of search with a budget (thinking_effort and thinking_timeout_s); also, the user can pick a metric, which might be the objective of some optimization; It would also make sense given the team’s AutoML background.
If we assume that Thinking mode is search with a budget, the big question would be: What is the search space? Does it include feature engineering? Is it about smart context selection? Is it maybe a more task-specific way of constructing a TabPFN ensemble? The gain in performance (in Elo) is quite large, so I’m assuming that it’s optimizing multiple things, not just a bit of feature engineering or so.
Another possibility is that Thinking mode does some type of context distillation or optimization, which might explain the strong gains on large datasets.
I am also wondering whether the Thinking procedure is model-agnostic. And if it is, would it give the same gains to xgboost and co, or is there something about tabular foundation models that makes the Thinking mode more effective?
These are my thoughts so far. I know, I am leaving you with more questions than answers 😅. What are your guesses?
I would guess they are training something like a LoRA with the search being a non-gradient based optimization instead of the typical gradient based iterative update.
That would make sense to do at fit time. Have negligible inference time impact as it works with base model and is efficient to store per user/customer. Base model effectively contains many priors and objectives from pre training. This likely would apply an application specific balance adjustment.
I wonder if some more testing might show a pattern in inference time delta between thinking and base models that might help narrow the possibilities.