
One model or many? Balancing entity-specific effects in prediction tasks

What do you do in the following scenario?
You have a prediction task for different entities. This could be forecasting sales for various stores or predicting customer churn for different customer segments.
You can train on one model for all entities and use the entity ID as a feature1 or train one model per entity.
What’s the better option?
The short answer would be: Whatever brings better predictive performance. So you can easily validate in your model selection step which strategy works better. Just as would be expected from a supervised ML mindset.
But predictive performance is not everything, and we can also get insights about the prediction task through learning which strategy works better. Let’s take a closer look at inductive biases indicated by the two choices.
Let’s make this more concrete: Let’s say you have to forecast next month’s water inflow for various dams. The features are 1) water flow the month before, 2) month, and 3) forecasted precipitation. For the entity-as-feature solution, you also have the dam ID as a feature.
Let’s look at two extreme scenarios of what the “true” prediction function could look like:
No dam-specific effects, but only general effects: This means that the true function of water flow given the features looks the same for all dams.
Each dam has a completely different dynamic: When you train a model for one dam, it would be completely useless for predicting another dam’s water flow since the relation between the features and the next month’s water flow is completely different between two dams.
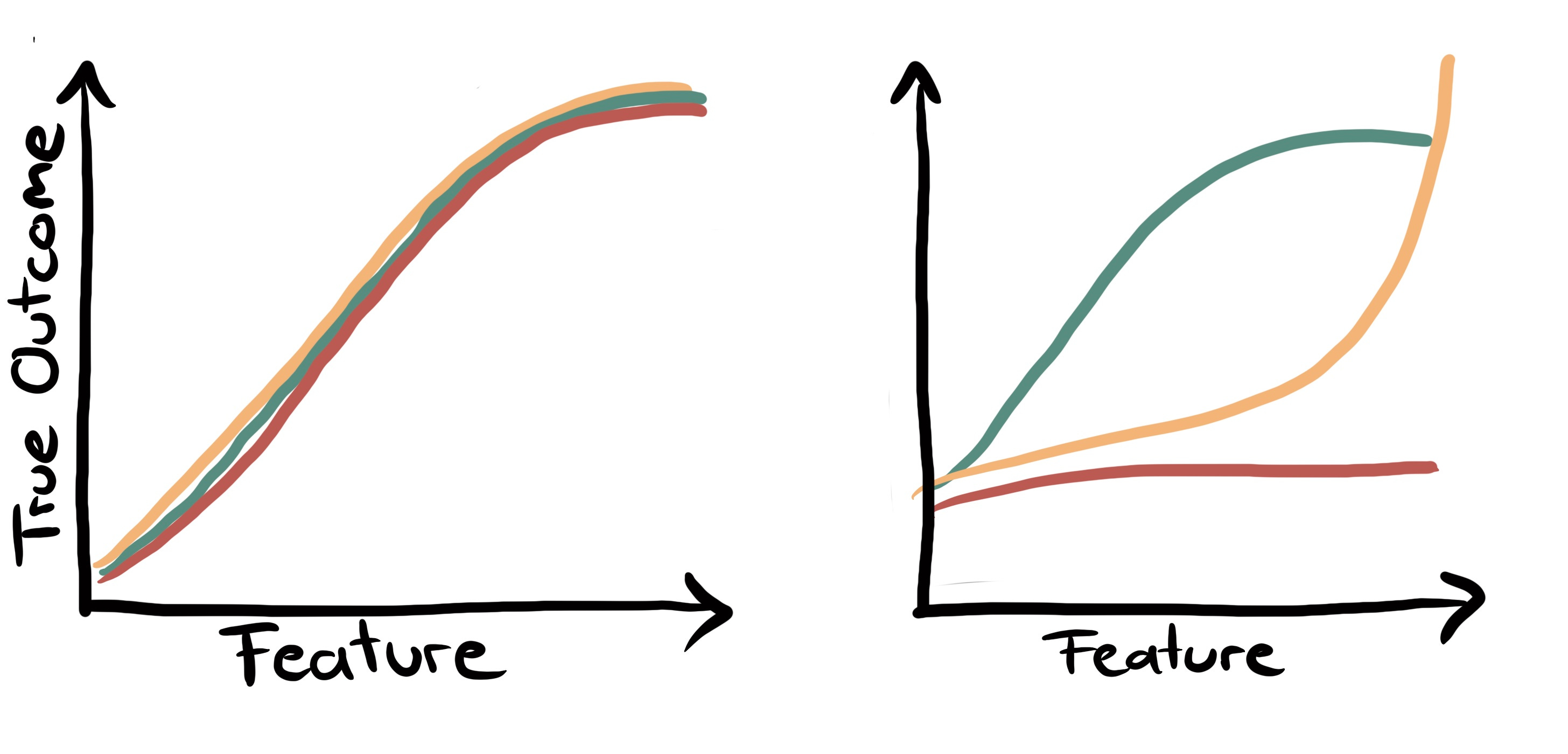
Both scenarios are unrealistic extremes, but every prediction task based on entities is a mixture of these two extreme scenarios: Typically you would expect at least some general patterns, for example, a high flow last month will mean a higher flow next month, regardless of the dam. But you would also expect individual effects, for example for one dam the precipitation forecast might be more relevant than for another.
Technically, we can describe this in the language of main effects and interactions: The general effects are main effects and interactions that don’t include entity-specific attributes (like the ID). The entity-specific effects are all interactions that include the entity ID or attributes that are fixed per entity (e.g. elevation of the dam). Related to this is my post on functional decomposition.
Let’s come back to the two solutions and how they would perform in these two extreme scenarios:
Scenario: There are only general effects.
When training one model and using entity ID as feature, it should work well. The ML algorithm only has to learn a model of the general effects while ignoring the entity ID feature.
Training one model per entity is problematic since each time the algorithm has to learn the same model but has much smaller data sets available, introducing a small sample bias.
Scenario: there are only entity-specific effects.
Training a model with entity as a feature: The ML algorithm has to learn all the interactions between the entity ID and the features. How well that works depends on the ML algorithm and the inductive biases it comes with. Tree-based algorithms work well here since they can split by entity ID and therefore emulate the split-by-entity modeling.
For training one model per entity it’s the ideal scenario, since the models need to be completely different anyway.
The beautiful thing about performance-based evaluation is that if one of the two strategies wins, you also learn something about the prediction task. If the one model per entity strategy has a better performance, it means that there are mostly entity-specific effects.
In general, I tend to pack everything into one model. For starters, I am often too lazy to implement an additional logic that splits the data by entity and then stores multiple models and so on. Such a hassle. Also, when using tree-based algorithms like the random forest, Catboost, or XGBoost, they can handle entity-specific effects very naturally since they kind of emulate the model-per-entity approach when they split by entity ID. They can be even more “clever” about it since they can bundle entities that have similar relations between features and outcome.
However, there are also advanrtages to training individual models, for example when pooling data raises major issues because of data privacy (e.g. hospital data). The one model per entity approach also makes it simpler to retrain a model if you just need to update one entity.
I’m talking about prediction tasks where the entities don’t change over time, so it’s not about e.g. forecasting for new stores but for the same ones in the training data.
Hello, Cristoph, very interesting article!
I work in unsupervised anomaly detection where the concept of entity is involved (different users / machines in this case), in this case, performance based evaluation is harder since labels are very scarce, would it be possible to apply some kind analysis to determine which option may be more suitable (besides the typical initial EDA to analyze the behavior/distribuitions of the different entities)?
Thanks!
This is a recurrent problem in demand forecasting: do we train one model per brand? per client? Then we have thousands of models and its post-mortem analysis becomes a nightmare. What if we train less models? Then performance tends to drop a bit. This is a never ending problem in my day to day work.